 — Никто не обнимет необъятного!
— Никто не обнимет необъятного!
Козьма Прутков, «Плоды раздумья», 67 афоризм, 1854
Одно из интересных и полезных применений нейросетей — обнаружение объектов на изображении, таких как машины, люди или человеческие лица.
Глубокое погружение в тему нейросетей требует немало времени и сил, а также определенных знаний в области математики. Хорошая новость в том, что уже созданы фреймворки, пригодные для применения в реальных проектах без предварительной фундаментальной подготовки программистов.
Вы, наверное, слышали, что для работы нейронных сетей требуются большие вычислительные мощности. После чтения нашей статьи вы сможете убедиться, что обнаружение объектов на уже обученных моделях нейросетей доступно для устройств с микрокомпьютерами, такими как Repka Pi.
В этой статье мы рассмотрим основные понятия нейронных сетей. Затем мы расскажем, как добавить функции обнаружения лиц и людей в видеопотоке от обычной веб-камеры, подключенной через USB к Repka Pi. При этом будут использованы каскады Хаара, нейросеть Yolo-FastestV2, фреймворки OpenCV и NCNN, а также репозиторий ml-repka от компании Rainbowsoft.
Формат статьи не позволяет рассказать подробно о том, как устроены и работают нейронные сети, тут потребуется не одна книга. Тем не менее, наша статья может послужить стартом для тех, кто собирается изучать нейросети, а также для тех, кто хочет добавить возможность обнаружения объектов в свое микрокомпьютерное устройство.
Для получения более глубоких знаний вы можете изучить материалы, на которые в нашей статье сделаны ссылки.
Оглавление #
Сборка макета для обнаружения лиц и людей
Исходные коды программ обнаружения
Нейроны человеческого мозга #
Можно только удивляться невероятным возможностям головного мозга человека в плане распознавания объектов. Человеку достаточно увидеть какой-то новый предмет всего несколько раз, и он уже практически безошибочно будет выделять его среди других предметов.
Как написано в Википедии, мозг содержит порядка 90—96 миллиардов нейронов, и гораздо больше связей между ними. Нейроны представляют собой специальные клетки, способные получать, обрабатывать, хранить и передавать информацию с помощью электрических и химических сигналов.
Устройство нейрона схематически показано на рис. 1.
{kind=link}
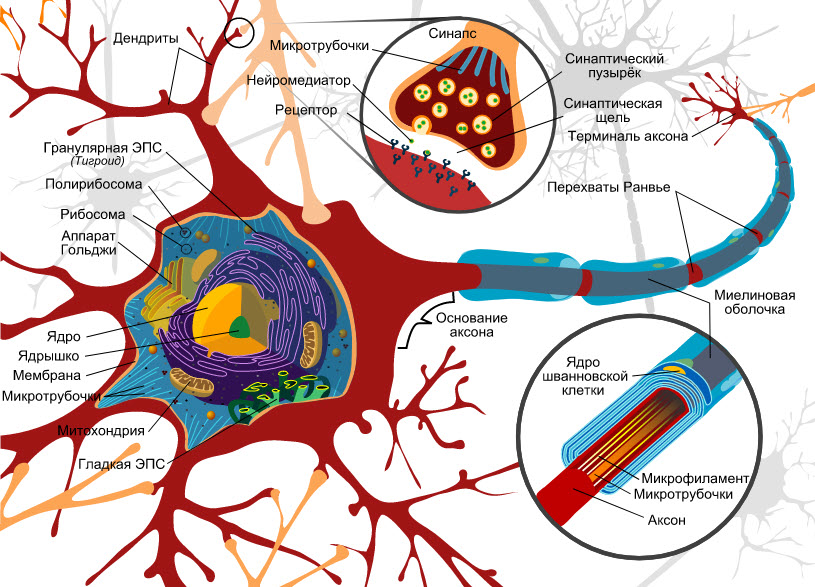 Рис. 1. Устройство нейрона
Рис. 1. Устройство нейрона
Не вдаваясь в детали, расскажем кратко о работе нейронов.
Нейроны получают сигналы, несущие информацию, через дендриты (возбуждающие или подавляющие), и поступают в ядро нейрона. Если сумма сигналов оказывается достаточно большой, нейрон переходит в возбужденное состояние.
Сигнал от возбужденного нейрона передается в аксон — отросток нейрона. Его длина может быть весьма небольшой или наоборот, достигать одного метра и более.
Когда сигнал достигает конца аксона, в пространство между нейронами выделяются нейромедиаторы — биологически активные химические вещества.
Эти нейромедиаторы могут возбудить или подавить активность другого нейрона, «подключенного» к аксону другого нейрона через синаптическое пространство между нейронами.
Алгоритм перехода биологического нейрона в возбужденное состояние сложен и его трудно, если вообще возможно, полностью смоделировать. Есть даже предположения, что в этом алгоритме задействованы квантовые эффекты.
Математическая модель нейрона #
Для моделирования нейронных сетей с помощью компьютеров была создана сильно упрощенная математическая модель нейрона (рис. 2).
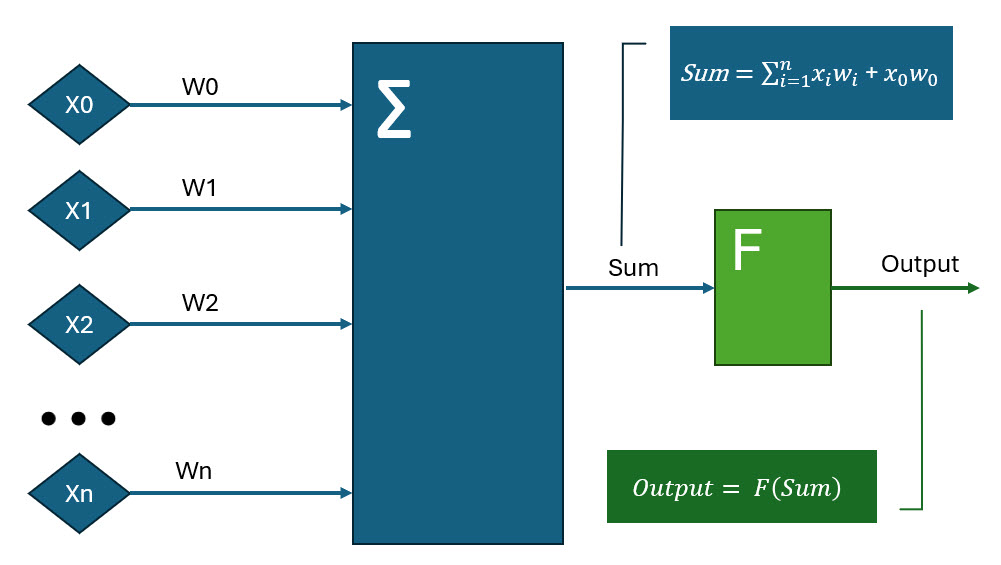
Рис. 2. Математическая модель нейрона
Здесь входные сигналы X0…Xn попадают на вход взвешенного сумматора, при этом веса W0…Wn определяют «вклад» каждого сигнала на итоговую сумму Sum. Этот вклад может быть положительным или отрицательным, увеличивающим или уменьшающим значение суммы. Сигнал W0 и соответствующий ему вес W0 может использоваться для инициализации нейрона.
Результат вычисления взвешенной суммы попадает на вход передаточной функции F (ее также называют функцией активации). Эта функция определяет зависимость выходного сигнала нейрона от взвешенной суммы сигналов на его входах. Обычно активация наступает при превышении определенного порога.
На практике применяются линейные и сигмоидные функции, функции гиперболического тангенса, функции Rectified Linear Unit (выпрямленный линейный блок), Leaky ReLU и другие (рис. 3). В статье Функция активации вы найдете описания, сравнение и графики различных функций.
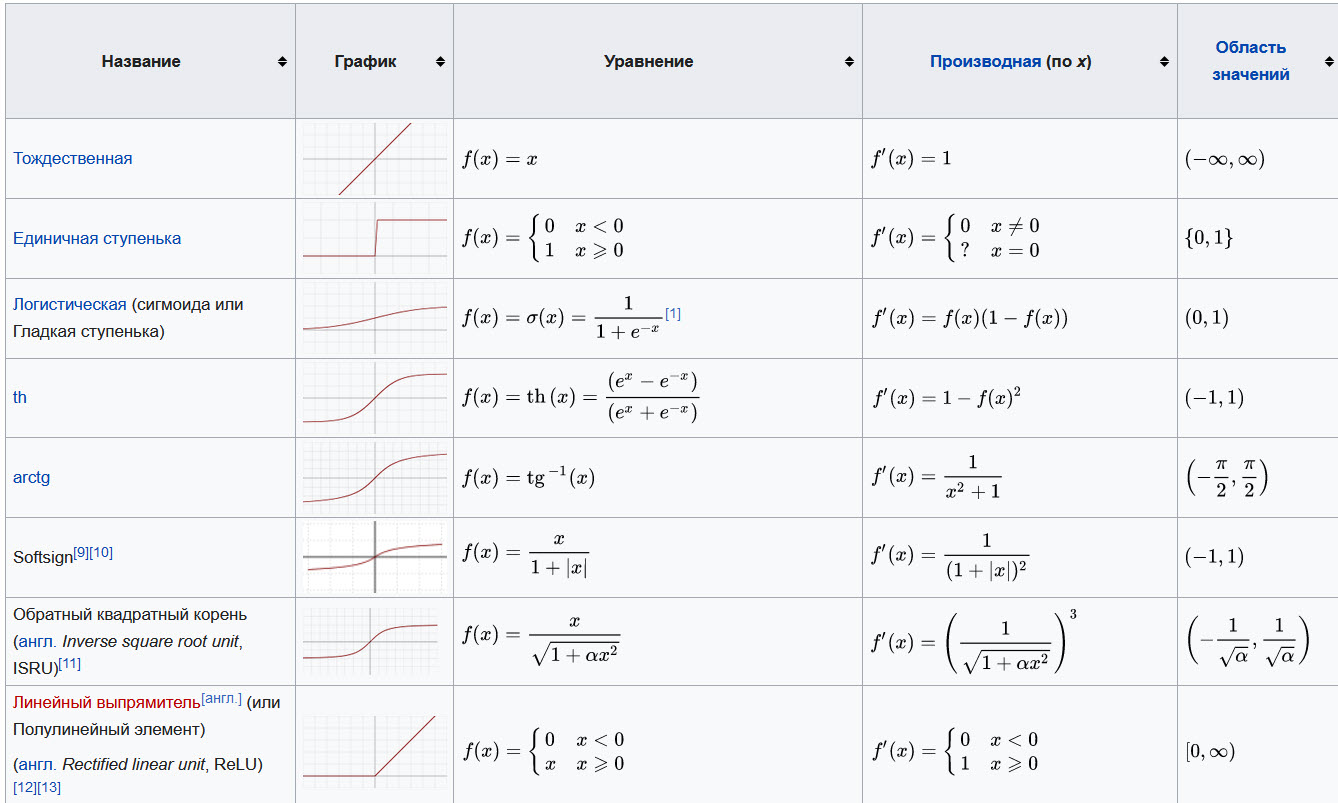 Рис. 3. Некоторые из функций активации
Рис. 3. Некоторые из функций активации
Какую из функций следует использовать?
Тут нет однозначного ответа. Функция активации влияет на скорость обучения и работы сети. Она может подбираться в процессе экспериментов или исследований. Когда вы имеете дело с готовыми моделями нейросетей и фреймворками, вам не придется выбирать функцию активации самостоятельно.
Архитектуры нейронных сетей #
Рассмотрим некоторые архитектуры и алгоритмы нейронных сетей — перцептрон, сверточные сети, YOLO и каскады Хаара.
Перцептрон #
В предыдущем разделе мы рассмотрели математическую модель нейрона. Такие нейроны можно комбинировать в нейронную сеть, пригодную, например, для распознавания простейших изображений.
На рис. 4 мы показали так называемый перцептрон — простейший вид нейронной сети.
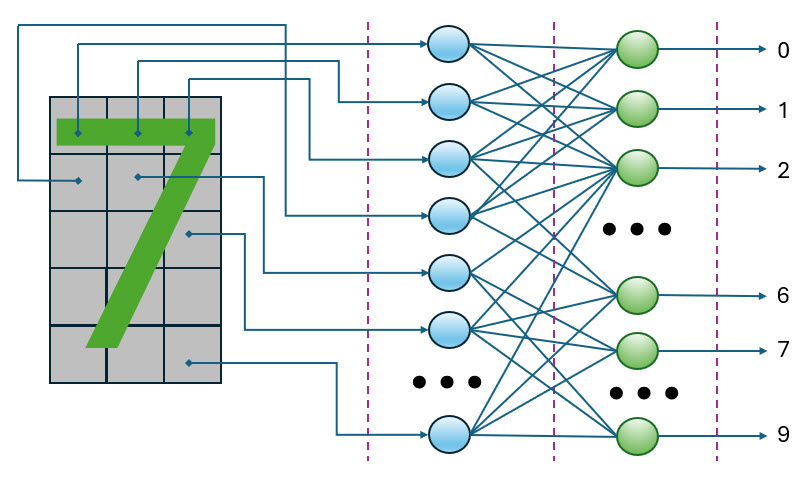 Рис. 4. Использование перцептрона для распознавания цифр
Рис. 4. Использование перцептрона для распознавания цифр
Представленный на рис. 4 перцептрон состоит из входного и выходного слоев. Предполагается, что этот перцептрон используется для распознавания цифр в диапазоне от 0 до 9.
В левой части рисунка показана матрица, в узлах которой находятся фотоэлементы или аналогичные устройства. Эти устройства способны посылать в нейроны входного слоя сигналы 0 или 1 в зависимости от того, перекрыт фотоэлемент изображением цифры, или нет.
Выходы нейронов первого слоя соединены со входами второго, выходного слоя нейронов. Хотя на рис. 4 это и не показано, предполагается, что каждый выход нейрона входного слоя соединен со входами всех нейронов выходного слоя.
Выходной слой содержит ровно десять нейронов, по одному на каждую цифру.
В процессе обучения сети предъявляются разные цифры и настраиваются веса для нейронов выходного слоя таким образом, чтобы активировался только тот нейрон, который соответствует предъявленной цифре. Заметим, что входной слой нейронов предназначен только для передачи сигналов от фотоэлементов на нейроны выходного слоя, и его веса в процессе обучения не изменяются.
Для обучения данной сети используется так называемый метод коррекции ошибки.
На первом шаге с помощью генератора случайных чисел всем весам присваиваются небольшие значения. Далее перцептрону предъявляется одна из цифр, после чего для каждого нейрона вычисляется его ошибка. Затем производится корректировка весов, и ошибка вычисляется снова.
Вся эта процедура повторяется необходимое количество раз до тех пор, пока ошибка не исчезнет. Подобное обучение нужно будет провести для каждой цифры, но что может уйти довольно много времени.
В этой статье вы сможете найти более подробное изложение алгоритма обучения перцептрона.
Возможно вам также будет интересно познакомиться с историей появления перцептрона Розенблатта в статье Всё, что вы хотели знать о перцептронах Розенблатта, но боялись спросить.
Сверточные сети #
Как вы уже, наверное, догадались, перцептрон плохо подходит для распознавания объектов на изображениях в реальном времени, не говоря уже о кадрах видеопотоков.
Представьте себе, что размер изображения составляет 640 на 480 пикселов. При этом во входной нейронной сети, подобной описанной выше, нужно будет использовать 307 200 нейронов.
Если нужно распознавать, например, 2000 объектов, то в выходном слое будет 2000 нейронов. Каждый выход 307 200 входных нейронов нужно будет подключить ко всем входам 2000 выходных нейронов. Получится, что между входным и выходным слоями будет нужно создать 2000 * 307 200 связей. Итого будет 614 400 000 связей, и для каждой связи в процессе обучения нужно будет настраивать свой вес. Таким образом, обучение превращается в очень сложную и ресурсоемкую процедуру.
В процессе распознавания по обученной сети, содержащей сотни тысяч нейронов и сотни миллионов связей также придется делать очень много вычислений. Такой процесс распознавания по обученной сети называется инференсом.
Но наша нас цель — организовать обнаружение объектов, для которых обучение не выполнялось, причем в реальном времени. Например, обнаружить и выделить на фотографии или в видеопотоке лица или фигуры людей (или других объектов), которые нейронная сеть никогда не «видела».
Перцептрон с этой задачей не справится из-за своих ограничений. Но главное — перцептрон не учитывает особенности изображений, в частности, взаимное расположение частей изображения. Перцептрон работает с векторами, и в нем нет ничего специального для поиска объектов на изображениях.
Для решения задач компьютерного зрения, классификации и сегментации изображений, а также для обнаружения объектов были созданы так называемые сверточные нейронные сети (Convolutional Neural Network, CNN).
Сверточные сети учитывают двумерную топологию изображений. Они устойчивы к небольшим смещениям, изменениям масштаба и поворотам объектов на входных изображениях.
На рис. 5 показана архитектура сверточной нейронной сети.
{kind=link}
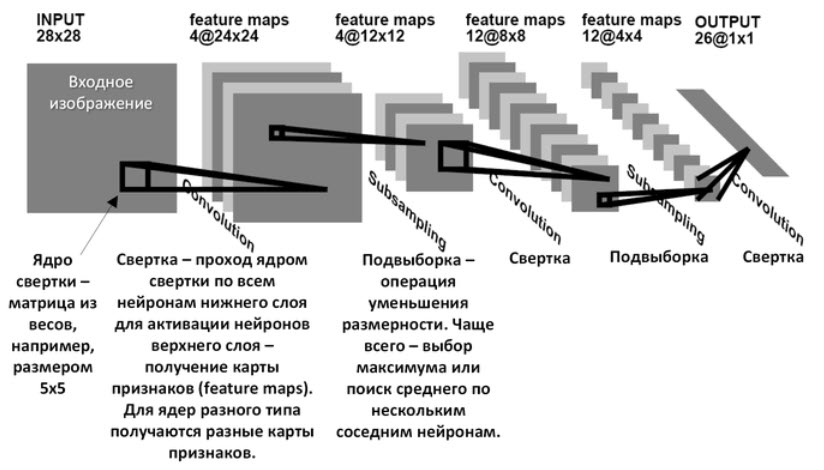 Рис. 5. Архитектура сверточной нейронной сети
Рис. 5. Архитектура сверточной нейронной сети
Можно выделить следующие компоненты сверточной нейронной сети:
- сверточные слои (Convolutional Layers);
- слои подвыборки (Pooling Layers);
- слой активации;
- полносвязные слои (Fully Connected Layers)
Сверточные слои позволяют нейронной сети «понимать» изображения, выделяя на них важные особенности, такие как грани, текстуры или формы объектов. Свертка позволяет обнаруживать различные уровни абстракции — низкоуровневые, такие как края и текстуры, и более высокоуровневые, такие как формы и объекты.
Слои подвыборки уменьшают размерность пространства признаков, уплотняя их представление и извлекая наиболее значимые признаки из каждой области. Это помогает улучшить распознавание при изменении масштаба изображения, а также при сдвигах объектов на изображении.
Слой активации играет роль функции активации, которая применяется к каждому числу входного изображения (рис. 3). Слой активации может быть встроен в сверточный слой, и не показан на рис. 5.
Полносвязные слои содержит матрицы весовых коэффициентов и векторы смещений. Они используются для классификации или регрессии.
Сверточная сеть обучается с помощью алгоритма обратного распространения ошибки. Сначала выполняется прямое распространение от первого слоя к последнему, после чего вычисляется ошибка на выходном слое и распространяется обратно. При этом на каждом слое вычисляются градиенты обучаемых параметров, которые в конце обратного распространения используются для обновления весов с помощью градиентного спуска.
Операция обучения сверточной сети, как и перцептрона, длительная и достаточно ресурсоемкая.
Алгоритм обнаружения объектов YOLO #
Алгоритм YOLO («Вы смотрите только один раз», You Only Look Once) представляет собой чрезвычайно быстрый алгоритм обнаружения объектов, использующий сверточную нейронную сеть, и способный работать в режиме реального времени.
Алгоритм YOLO был представлен в 2015 году Джозефом Редмоном, Сантошем Диввалой, Россом Гиршиком и Али Фархади в исследовательской работе You Only Look Once: Unified, Real-Time Object Detection.
В этой работе проблема обнаружения объектов формулируется как задача регрессии, а не классификации. Регрессия выполняется с помощью пространственного разделения ограничивающих рамок и связывания вероятностей с каждым из обнаруженных изображений. При этом используется одна сверточная сеть.
При использовании YOLO для ускорения обнаружения объектов предлагается выбрать в изображении некоторое фиксированное количество прямоугольников и для каждого прямоугольника проверить наличие искомого объекта. Если объект найден, для него определяется класс принадлежности и координаты рамки, окружающей этот объект — bounding box.
На рис. 6 показано обнаружение лиц, выполненное с помощью микрокомпьютера Repka Pi.
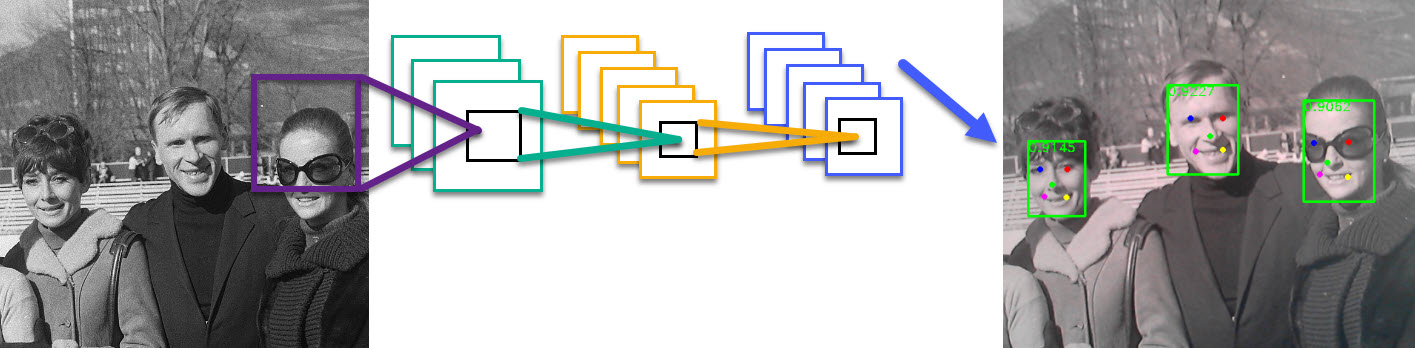 Рис. 6. Обнаружение лиц с помощью Repka Pi
Рис. 6. Обнаружение лиц с помощью Repka Pi
Класс принадлежности объекта — это такие категории, как «автомобиль», «дом», «пешеход», «стол», «машина», «грузовик», «автобус» и так далее.
Для каждого обнаруженного объекта YOLO возвращает рамку, окружающую этот объект (bounding box), а также вероятность принадлежности к тому или иному классу.
Скорость базовой модели YOLO, по сообщениям ее создателя, такова, что она способна обрабатывать изображения в режиме реального времени со скоростью 45 кадров в секунду (с использованием процессора Titan X GPU). Скорость обработки сети Fast YOLO достигает 155 кадров в секунду.
Как достигается такая высокая скорость обработки?
В отличие от традиционных сверточных сетей, YOLO способна обнаружить объекты за один проход по изображению, вместо множества таких проходов. Это существенно уменьшает время работы алгоритма. Во время этого единственного прохода с помощью сверточных слоев из изображения извлекаются признаки. В результате нет необходимости многократного выполнения свертки и пулинга.
Далее, YOLO разбивает изображение на сетку ячеек и предсказывает объекты, находящиеся в каждой ячейке. В результате алгоритм может эффективно обрабатывать изображения большого размера.
Архитектура YOLO позволяет задействовать мощности графических процессоров GPU. Это дает дополнительную прибавку скорости при работе сети на компьютерах, оснащенных такими процессорами.
Надо сказать, что YOLO обрабатывает изображения с низким разрешением, что уменьшает необходимое количество операций, и ускоряет алгоритм.
Каскады Хаара #
В одной из программ, приведенных в этой статье, мы будем использовать каскады Хаара. Этот классический метод компьютерного зрения был предложен Паулем Виолой и Майклом Джонсом еще в 2001 году. Он основан на применении набора простых признаков (например, границы и текстуры) к изображению с использованием фильтров Хаара.
Каскады Хаара эффективны для обнаружения объектов с фиксированным размером и формой, таких как лица. Однако он не обладает высокой точностью и часто требует тщательной настройки для различных типов объектов.
Другие архитектуры #
Сравнительное описание других архитектур нейросетей вы найдете в статье Распознавание образов с помощью искусственного интеллекта.
Сборка макета для обнаружения лиц и людей #
А теперь перейдем к практической части — на базе микрокомпьютера Repka Pi и видеокамеры USB соберем макет, способный обнаруживать в видео потоке лица и фигуры людей.
Подключите к разъему USB микрокомпьютера Repka Pi веб-камеру, такую как Logitech HD 720p или аналогичную (рис. 7).
 Рис. 7. Веб-камера Logitech HD 720p подключена к Repka Pi через USB
Рис. 7. Веб-камера Logitech HD 720p подключена к Repka Pi через USB
Мы будем обнаруживать и выделять в потоке данных от веб-камеры лица и людей.
Желательно, чтобы в микрокомпьютере была установлена память объемом не менее 2 ГБайт. Это сильно ускорит сборку необходимого ПО, особенно фреймворка OpenCV.
Также обратим ваше внимание на необходимость охлаждения процессора, если для повышения скорости обнаружения объектов он будет работать на повышенной частоте. Обязательно используйте вентилятор.
Установка Repka OS #
Перейдем к установке ПО. Процесс установки длительный, может отнять у вас несколько часов.
Вы можете установить все самостоятельно или скачать готовый образ ml-repka-arm64_ubuntu_20.04.6_desktop_13.06.24_ver-1.6.7z, размещенный на этой странице. В готовом образе используются такие настройки сети:
-
сеть 192.168.0.0/24
-
адрес узла 192.160.0.47
-
шлюз и DNS 192.168.0.1
При самостоятельной установке скачайте образ Repka OS с сайта по ссылке на раздел с образами прошивки. Мы использовали образ версию прошивки от 13.06.24, так как как раз разработчики объявили, что провели адаптацию и доработку операционной системы для работы именно с нейронными сетями, сделав её стабильной и более эффективной в сравнении с предыдущими версиями операционной системы - эта версия (или выше) рекомендуется для работы с нейросетями, так как в ней доработаны параметры работы регулятора питания на длительных непрерывных максимально высоких нагрузках при большом объёме данных передаваемых в оперативную память. Эта версия Repka OS доступна для всех версий плат Repka Pi 3, а мы применяли два экземпляра - версии 1.3 и версии 1.6, но для версии 1.6 выбрали вариант, предназначенный для варианта режима работы с активным охлаждением, так как без охлаждения одноплатники на задачах распознавания могут греться и снижать частоту работы, это называется тротлить, что будет приводить к снижению производительности, а на таких задачах это не очень интересно, а точнее совсем не интересно.
Запишите образ на карту памяти, объемом не менее 32 Гбайт.
Из консоли обновите пакеты:
# apt update
# apt upgrade
Далее для настройки производительности запустите программу repka-config:
# repka-config
Выберите в меню строку 3 Interface Options (Настройка подключения и интерфейсов), затем I2 Frequency / pinout Options (Настройка производительности и распиновки).
Для Repka Pi версии 1.3 мы выбрали частоту 1.368 ГГц (рис. 8), а для Repka Pi версии 1.6 — частоту 1.416 ГГц с активным охлаждением.
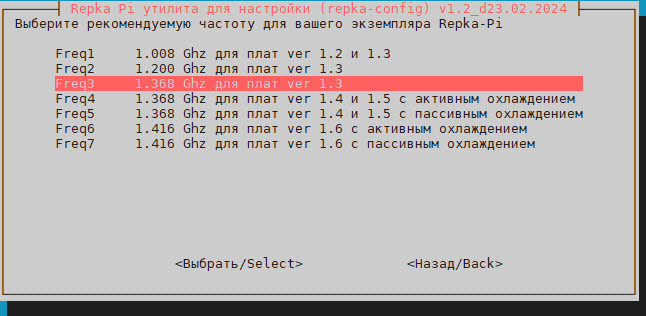 Рис. 8. Выбор частоты процессора
Рис. 8. Выбор частоты процессора
Если у вас Repka Pi с платой версии 1.4, 1.5 или 1.6, для максимальной производительности, выбирайте вариант с максимальной частотой процессора и с активным охлаждением. И, конечно, не забудьте установить вентилятор.
Мы запускали ПО на Repka Pi версии 1.3, поэтому выбрали первый вариант распиновки. После выбора мы перезагрузили Repka OS.
Далее нам потребуется ядро ОС 6.1.11. Запустите программу repka-config. Выберите строку System Options (Настройка системы), затем строку S1 Select-Kernel (Выбрать ядро Linux). Вы увидите текущую версию ядра. Далее нажмите кнопку OK и выберите ядро 6.1.11-sunxi64 (рис. 9).
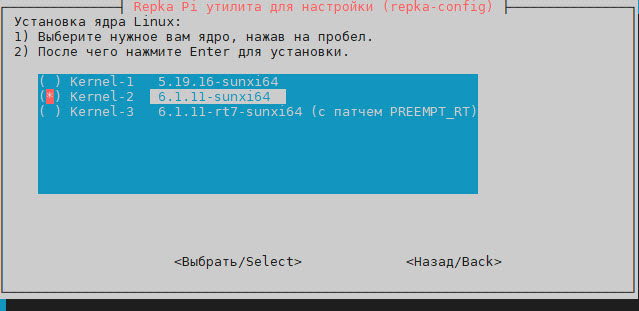 Рис. 9. Выбираем версию ядра ОС
Рис. 9. Выбираем версию ядра ОС
После перезагрузки проверьте версию ядра:
# uname -a
Linux Repka-Pi 6.1.11 #2 SMP Wed Jan 17 16:29:59 +04 2024 aarch64 aarch64 aarch64 GNU/Linux
Загрузка файлов репозитория #
Теперь можно переходить к установке репозитория и фреймворков.
Прежде всего создайте рабочий каталог, например, workspace, и загрузите и распакуйте файлы репозитория ml-repka:
# mkdir workspace && cd workspace
# git clone https://gitflic.ru/project/repka_pi/ml-repka.git
Установка Golang #
Скачайте и распакуйте файлы Golang:
# wget https://go.dev/dl/go1.22.3.linux-arm64.tar.gz
# tar -C /usr/local -xzf go1.22.3.linux-arm64.tar.gz
Файлы будут распакованы в каталог /usr/local, поэтому распаковку нужно выполнять с правами пользователя root.
Отредактируйте файл ~/.profile или ~/.bashrc, добавив в конце файла строку:
export PATH=$PATH:/usr/local/go/bin
Актуализируйте файл профиля и проверьте версию Golang:
# source ~/.profile
# go version
go version go1.22.3 linux/arm64
Установка OpenCV #
На следующем этапе мы будем собирать и устанавливать OpenCV.
Библиотека (фреймворк) OpenCV (Open Source Computer Vision Library) предназначена для разработки приложений компьютерного зрения. В ней имеется набор инструментов и функций для работы с изображениями и видео, обнаружения объектов, анализа движения, калибровки камер, создания графических интерфейсов и многого другого.
Для выполнения установки OpenCV потребуется дополнительная память, поэтому размер файла Swap надо будет увеличить до 6 ГБайт, а затем перезагрузить ОС:
# swapoff /swapfile
# fallocate -l 6G /swapfile
# mkswap /swapfile
# swapon /swapfile
# reboot
После выполнения этих команд и перезагрузки убедитесь, что размер Swap увеличился до 6 Гбайт:
# swapon --show
NAME TYPE SIZE USED PRIO
/swapfile file 6G 0B -2
Если у вас Repka Pi с объемом оперативной памяти 1 Гбайт, необходимо на время установки увеличить размер раздела /tmp, размер которого по умолчанию составляет 477 MБайт. Для увеличения до 1 ГБайт используйте такую команду:
# mount -o remount,size=1G /tmp
Проверьте, что размер раздела увеличился:
# df -h /tmp
Файл.система Размер Использовано Дост Использовано% Cмонтировано в
tmpfs 1,0G 4,0K 1,0G 1% /tmp
После перезагрузки ОС размер этого раздела станет прежним.
Далее для запуска OpenCV перейдите в каталог install репозитория ml-repka и запустите установку:
# cd workspace/ml-repka/install
# time make install_raspi
С помощью команды time мы можем измерить длительность работы команды make.
Заметим, что на Repka Pi с объемом оперативной памяти 1 Гбайт сборка OpenCV может идти очень долго.
После завершения установки проверьте версию OpenCV:
# opencv_version
4.9.0
Если вам будут нужна дополнительные модели для нейросетей, то вы сможете их найти по адресу: https://download.repka-pi.ru/ml/. Загрузите их в следующие каталоги:
- yolov3.weights ==> humandetect_yolo/data (предварительно обученные веса для модели YOLOv3);
- frozen_inference_graph.pb ==> humandetect_tf/data (архитектура модели и обученные веса модели TensorFlow)
- yolov3-tiny.weights ==> humandetect_yolo_tiny/data (предварительно обученные веса для модели YOLOv3-Tiny)
Установка библиотеки NCNN #
Библиотека NCNN (Nihui Convolutional Neural Network) представляет собой библиотеку глубокого обучения с открытым исходным кодом. Эта библиотека оптимизирована для работы на мобильных и встраиваемых устройствах. С ее помощью можно эффективно выполнять инференс (прогнозирование) нейронных сетей на устройствах с ограниченными вычислительными ресурсами. Как мы уже говорили, инференс — это процесс работы обученной нейросети на конечном устройстве, или конечный результат обработки данных.
Для установки NCNN перейдите в рабочий каталог, выполните клонирование репозитория, а затем перейдите в полученный таким образом каталог:
# cd workspace
# git clone https://github.com/Tencent/ncnn.git
# cd ncnn
Далее обновите сабмодули репозитория:
# git submodule update --init
После этого нужно создать каталог для сборки и сделать его текущим, а затем подготовить репозиторий к сборке:
# mkdir build && cd build
# cmake -DCMAKE_BUILD_TYPE=Release -DNCNN_BUILD_EXAMPLES=ON -DNCNN_BUILD_TOOLS=OFF ..
Запустите сборку (это длительный процесс), а после ее завершения — установку NCNN:
# make -j2
# make install
Для установки переменной среды ncnn_DIR добавьте в файл ~/.profile или ~/.bashrc следующую строку:
export ncnn_DIR=/root/workspace/ncnn/build/install/lib/cmake/ncnn
Далее активируйте изменения в профиле:
# source ~/.profile
Вы также можете ознакомиться с документацией по установке репозитория ml-repka от компании Rainbowsoft.
Запуск программ обнаружения #
Чтобы оценить возможности микрокомпьютера Repka Pi, запустим некоторые программы, размещенные в репозитории ml-repka. Это программы обнаружения лиц, людей, а также программа сегментации людей.
Программа обнаружения лиц run-facedetect #
Чтобы запустить программу обнаружения лиц в потоке от видеокамеры run-facedetect, перейдите в репозиторий ml-repka и соберите программу с помощью make:
# cd workspace/ml-repka
# make build-facedetect
Далее запустите программу:
# make run-facedetect
Если программа не запускается, потому что не находит камеру, установите значение SOURCE равным 1 в файле workspace/ml_repka/Makefile и запустите команду «make build-facedetect» заново.
Вы можете проверить работоспособность камеры, подключенной к USB, и определить ее адрес следующим образом.
Прежде всего, используйте команду lsusb:
# lsusb
Bus 008 Device 002: ID 046d:c31c Logitech, Inc. Keyboard K120
Bus 008 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 007 Device 002: ID 046d:c05a Logitech, Inc. M90/M100 Optical Mouse
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 004 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 002: ID 046d:0825 Logitech, Inc. Webcam C270
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
В данном случае команда нашла веб-камеру Logitech, Inc. Webcam C270.
Далее при помощи следующей команды можно посмотреть список доступных устройств захвата:
# ls /dev/video*
/dev/video0 /dev/video1 /dev/video2
И, наконец, команда ffmpeg позволит вам не только проверить наличие веб-камеры, но и покажет доступные форматы видео для вашей веб-камеры, включая разрешения и кодеки, поддерживаемые каждым форматом:
# ffmpeg -f v4l2 -list_formats all -i /dev/video1
ffmpeg version 4.2.7-0ubuntu0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 9 (Ubuntu 9.4.0-1ubuntu1~20.04.1)
configuration: --prefix=/usr --extra-version=0ubuntu0.1 --toolchain=hardened --libdir=/usr/lib/aarch64-linux-gnu –
…
libpostproc 55. 5.100 / 55. 5.100
[video4linux2,v4l2 @ 0xaaab2345e760] Raw : yuyv422 : YUYV 4:2:2 : 640x480 160x120 176x144 320x176 320x240 352x288 432x240 544x288 640x360 752x416 800x448 800x600 864x480 960x544 960x720 1024x576 1184x656 1280x720 1280x960
[video4linux2,v4l2 @ 0xaaab2345e760] Compressed: mjpeg : Motion-JPEG : 640x480 160x120 176x144 320x176 320x240 352x288 432x240 544x288 640x360 752x416 800x448 800x600 864x480 960x544 960x720 1024x576 1184x656 1280x720 1280x960
После запуска программы run-facedetect мы направили веб-камеру на сайт Repka Pi. Результат обнаружения лиц показан на рис. 10.
 Рис. 10. Результат работы программы facedetect
Рис. 10. Результат работы программы facedetect
Как видите, здесь выделяются рамкой лица и так называемые метки лица — цветные точки. На рис. 11 показано исходное изображение и результат обнаружения лица в более крупном масштабе.
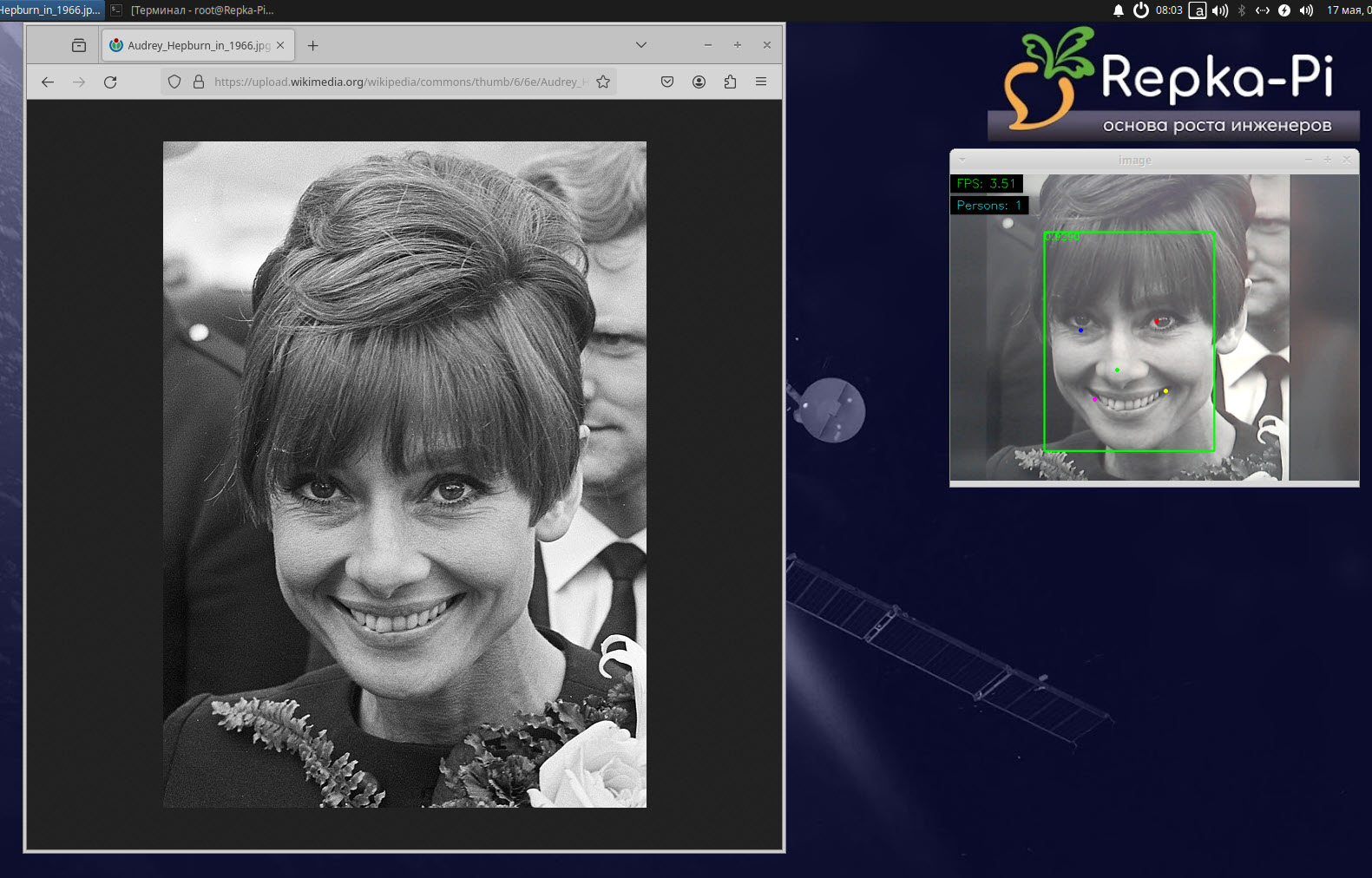 Рис. 11. Результаты обнаружения лица
Рис. 11. Результаты обнаружения лица
Метки лица (face landmarks) представляют собой точки, расположенные на ключевых областях лица, таких как глаза, нос, рот и так далее. Могут использоваться для обнаружения и отслеживания лиц, в качестве ориентиров для определения положения и ориентации лица в пространстве, для распознавания эмоций и выражений лица и других операций.
Программы обнаружения людей run-humandetect #
Теперь испытаем Repka Pi и YOLO для решения другой задачи — обнаружения людей и других объектов в потоке данных от веб-камеры.
Перейдите в репозиторий ml-repka и соберите программу с помощью make:
# cd workspace/ml-repka
# make build-humandetect
После сборки запустите программу:
# make run-humandetect
Результат работы программы обнаружения humandetect, запущенной на Repka Pi, показан на рис. 12.
 Рис. 12. Результат работы программы обнаружения объектов
Рис. 12. Результат работы программы обнаружения объектов
В заголовке каждой рамки обнаруженного объекта написано название класса и вероятность того, что объект принадлежит этому классу. Как видите, почти все люди были распознаны как объекты класса person, и лишь один оказался похож на стул (класс chair). Да, обнаржуение не всегда дает точные результаты, особенно если качество исходного изображения не слишком высокое.
На рис. 13 показано, как с помощью программы humandetect можно обрабатывать изображение трафика загруженного шоссе.
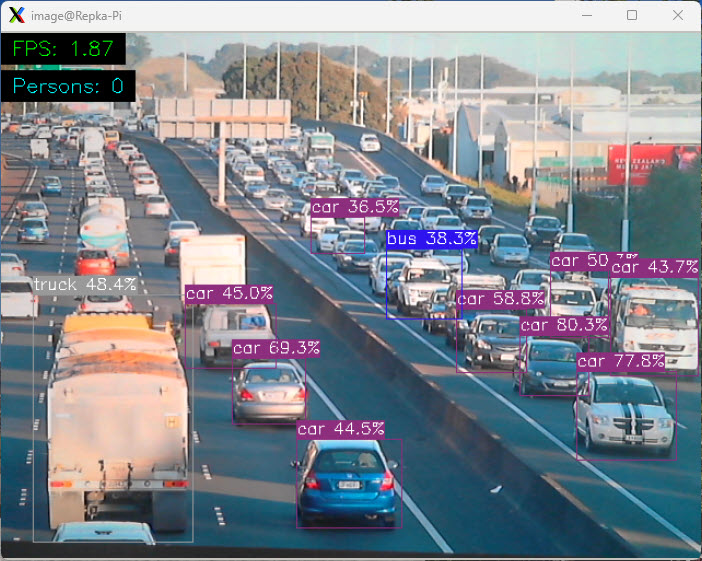 Рис. 13. Обработка фото трафика загруженного шоссе
Рис. 13. Обработка фото трафика загруженного шоссе
Как видите, программа обнаружила здесь автомобили класса car, автобус класса bus, а также грузовую машину класса truck.
Программа сегментации людей humanseg #
Программа humanseg может выполнить сегментацию людей. Запустите ее следующей командой:
# make humanseg
Направьте веб-камеру на изображение, где есть несколько человек, и вы увидите результат сегментации (рис. 15).
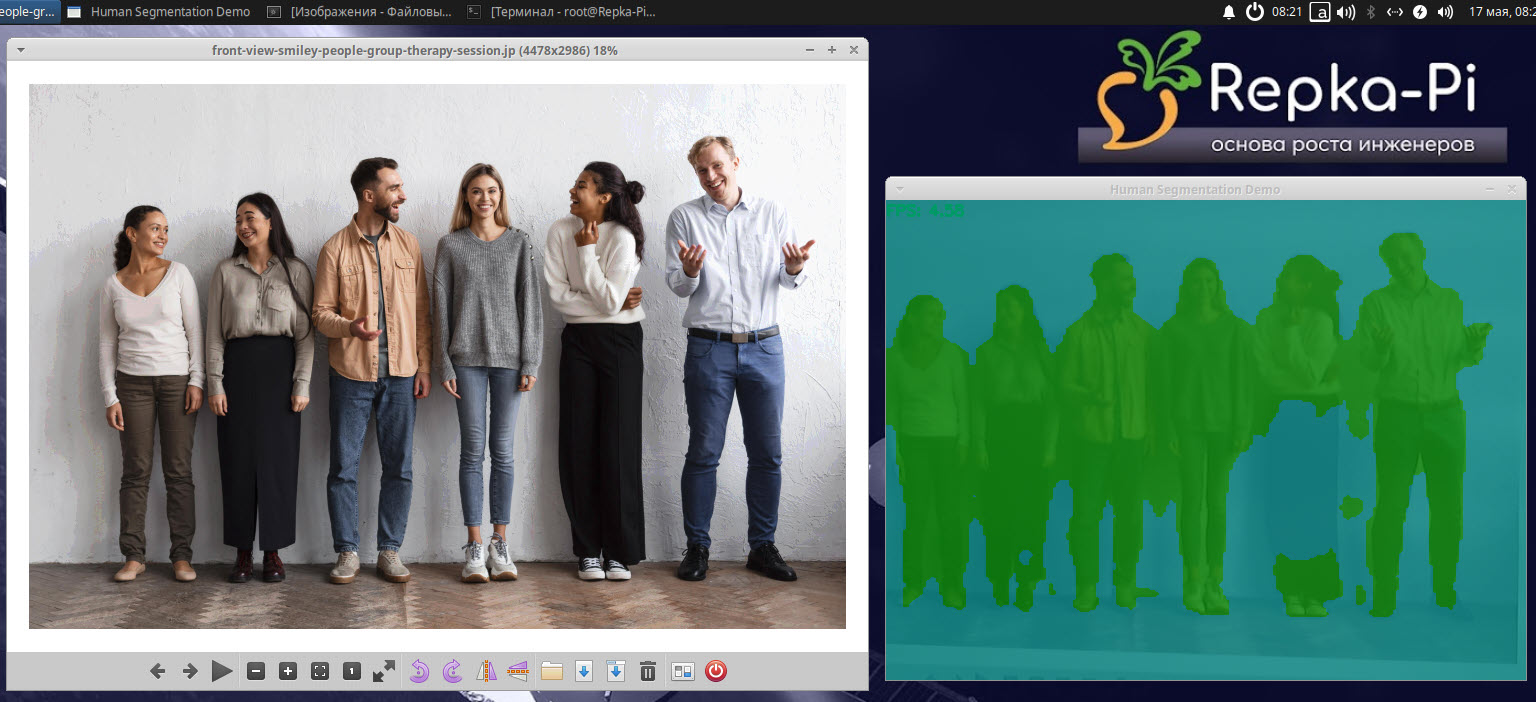 Рис. 15. Сегментация людей с помощью humanseg
Рис. 15. Сегментация людей с помощью humanseg
Здесь мы использовали исходное изображение, открытое на сайте Freepik.
В процессе сегментации исходное изображение было разделено на области, которые содержат людей. С помощью сегментации людей можно анализировать поведение, контролировать движения, анализировать сцены и так далее.
Как это видно на рис. 15, при сегментации могут возникать ошибки.
Другие программы обнаружения #
В репозитории ml-repka есть и другие программы обнаружения. Чтобы узнать их список и получить краткое описание, введите команду:
# make help
На рис. 14 мы показали часть программ, которые можно запускать на Репке (без докера).
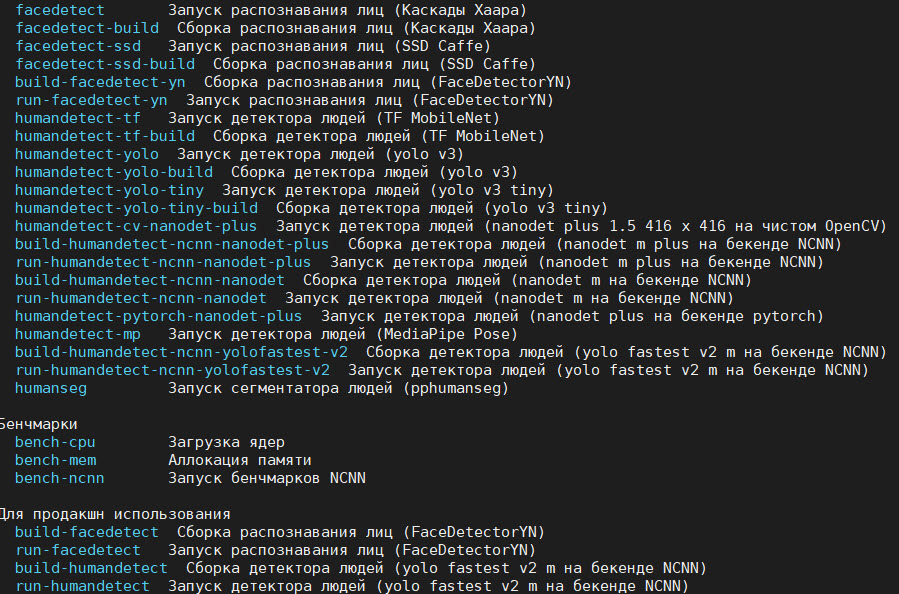 Рис. 14. Некоторые программы из репозитория ml-repka
Рис. 14. Некоторые программы из репозитория ml-repka
Мы оставим эти программы вам на самостоятельное изучение.
В статье Deep learning examples on Raspberry 32/64 OS вы найдете обзор различных моделей нейросетей и примеры их использования для решения таких задач:
- обнаружение объектов;
- сегментация;
- оценка позы;
- классификация;
- обнаружение масок на лицах людей;
- обнаружение лиц;
- отслеживание объектов;
- определение положения головы;
- обнаружение текста;
- увеличение изображений без потери деталей;
- раскрашивание черно-белых изображений;
- реконструкция лица;
- управление парковками
Исходные коды программ обнаружения #
Далее мы приведем краткое описание исходных кодов некоторых программ обнаружения из репозитория ml-repka. Это программы facedetect-yn, facedetect, humandetect и humanseg.
Программа facedetect-yn #
Ранее вы запускали программу обнаружения лиц следующей командой:
# make run-facedetect
При этом выполняется программа run-facedetect-yn. Эта программа использует быструю и точную сверточную сеть для обнаружения лиц YuNet. Для обнаржуения лиц программа run-facedetect-yn использует предварительно обученную модель в формате ONNX (Open Neural Network Exchange).
Исходный текст программы run-facedetect-yn вы найдете в листинге 1. Для сокращения объема статьи мы не будем приводить и описывать его полностью.
Листинг 1. ml-repka/facedetect_yn/demo.cpp
В начале листинга подключаются заголовочные файлы OpenCV, а также стандартные библиотеки C++:
#include "opencv2/opencv.hpp"
...
После разбора параметров запуска, загрузки параметров модели инициализируется видео захват с веб-камеры и включается режим обработки исключений. Далее программа получает размеры кадров (ширину и высоту), которые будет захватывать устройство:
int device_id = parser.get("device_id");
auto cap = cv::VideoCapture(device_id);
cap.setExceptionMode(true);
int w = static_cast(cap.get(cv::CAP_PROP_FRAME_WIDTH));
int h = static_cast(cap.get(cv::CAP_PROP_FRAME_HEIGHT));
Далее создается экземпляр класса YuNet, настраивается и конфигурируется модель YuNet для обработки изображений с заданным размером и параметрами:
YuNet model(model path, cv::Size(w, h), conf_threshold, nms_threshold, top_k, backend_id, target_id);
Путь к файлу обученной модели path передается программе через параметры запуска.
Метод setInputSize устанавливает размер входного изображения, которое будет использоваться моделью для обработки:
model.setInputSize(cv::Size(w, h));
Далее запускается цикл, в котором захватываются кадры с камеры. Их размер изменяется для обработки моделью YuNet, после чего выполняется обнаружение лиц. В итоге на каждом шаге цикла результаты масштабируются обратно к исходному размеру и отображаются. На кадрах рисуются прямоугольники вокруг лиц и метки ключевых точек. При этом для оценки производительности оцениваются временные характеристики процесса.
Захват кадра выполняется методом cap.read:
bool has_frame = cap.read(frame);
Процедура предсказания (инференс) выполняется методом model.infer. При этом время выполнения инференса определяется методами tick_meter.start и tick_meter.stop:
tick_meter.start();
cv::Mat faces = model.infer(resized_frame);
tick_meter.stop();
Следующий фрагмент кода масштабирует результаты обнаружения лиц (координаты и размеры прямоугольников, а также координаты меток лица face landmarks) обратно к размеру исходного кадра:
for (int i = 0; i < faces.rows; ++i)
{
faces.at(i, 0) *= scale_x; // x1
faces.at(i, 1) *= scale_y; // y1
faces.at(i, 2) *= scale_x; // w
faces.at(i, 3) *= scale_y; // h
for (int j = 0; j < 5; ++j)
{
faces.at(i, 2*j+4) *= scale_x; // x для точек на лице
faces.at(i, 2*j+5) *= scale_y; // y для точек на лице
}
}
Далее с помощью функции visualize результаты рисуются на исходном кадре, и этот кадр отображается в окне "image":
auto res_image = visualize(frame, faces, (float)tick_meter.getFPS());
if (frame.empty()) {
continue;
}
cv::namedWindow("image", cv::WINDOW_NORMAL);
cv::imshow("image", res_image);
В конце цикла счетчик времени сбрасывается для измерений в следующем цикле обработки:
tick_meter.reset();
Программа facedetect #
Если вы создаете программы на языке Golang, вам пригодится исходный код программы facedetect, который есть в репозитории ml-repka и представлен в листинге 2.
Листинг 2. ml-repka/facedetect/main.go
В самом начале программы импортируются стандартные библиотеки, а также библиотеки для работы с компьютерным зрением и машинным обучением:
import (
"fmt"
"gocv.io/x/gocv"
"image"
"image/color"
"os"
wrapper "rainbowsoft.ru/ml_wrapper"
"strconv"
"time"
)
Библиотека gocv.io/x/gocv представляет собой обертку для фреймворка OpenCV, предназначенного для обработки изображений и видео, а также для разработки приложений компьютерного зрения.
Библиотека rainbowsoft.ru/ml_wrapper — это внешняя библиотека с обертками для машинного обучения от rainbowsoft.ru, предоставляющая удобные методы для работы с моделями машинного обучения.
Остальные библиотеки — стандартные. Библиотека fmt содержит методы для форматированного вывода данных, image — для работы с изображениями, image/color — для работы с цветами изображений, os — для работы с ОС, в частности, с файлами, strconv — для преобразования строк в числа и чисел в строки, time — для работы со временем.
В первой строке функции main задается путь к файлу предварительно обученной модели каскада Хаара для обнаружения лиц на изображениях:
xmlFile := "facedetect/data/haarcascade_frontalface_default.xml"
Метод компьютерного зрения с названием каскад Хаара применяется для обнаружения объектов в изображениях или видео. Он базируется на простых признаках, таких как изменение интенсивности пикселей.
Упомянутый выше XML-файл является частью библиотеки OpenCV. В нем содержится информация о структуре и весах признаков, необходимых для обнаружения лиц. В процессе обнаружения лиц каскад Хаара сканирует изображение с помощью окна фиксированного размера, которое перемещается по изображению. На каждом шаге каскад проверяет, соответствует ли область признакам, описанным в XML-файле, и принимает решение о том, содержит ли она лицо или нет.
Программе передаются два параметра — источник видео и ограничения на количество фреймов в секунду (Frame Per Second, FPS). Значения этих параметров записываются в переменные deviceID и fixedFPS, соответственно:
deviceID := os.Args[1]
fixedFPS, err := strconv.Atoi(os.Args[2])
Когда вы запускаете программу командой «make run-facedetect», то эти параметры передаются через Makefile:
SOURCE ?= 1 # Источник видео (Файл, вебка)
FPS ?= 0 # Ограничение FPS (0 - без ограничения)
Экспериментируя с программой обнаружения лиц, вы можете менять эти параметры.
После сохранения параметров запуска программа создает объект захвата видео, обращаясь для этого к методам NewVideoCapture и VideoCaptureOpen библиотеки ml_wrapper:
video := wrapper.NewVideoCapture()
err = wrapper.VideoCaptureOpen(video, deviceID)
if err != nil {
fmt.Println("Ошибка открытия видео потока:", err)
return
}
defer wrapper.VideoCaptureClose(video)
Обратите внимание, что при создании объекта захвата видео используется переменная deviceID — идентификатор источника видео, заданный в первом параметре запуска программы.
Если в этом параметра было указано целочисленное значение, то выбирается камера на устройстве по ее индексу. Если же значение представляет собой строку, то это может быть http-адрес видеофайла или локальный путь к видео файлу на микрокомпьютере.
На следующем шаге методом gocv.NewWindow создается окно для изображения с обнаруженными лицами. Также с помощью метода color.RGBA задается цвет рамки:
window := gocv.NewWindow("Face Detect")
defer window.Close()
blue := color.RGBA{0, 0, 255, 0}
Далее загружается XML-файл предварительно обученного классификатора обнаружения лиц методом каскадов Хаара:
classifier := gocv.NewCascadeClassifier()
defer classifier.Close()
if !classifier.Load(xmlFile) {
fmt.Printf("Error reading cascade file: %v\n", xmlFile)
return
}
Обработка потока видео выполняется в бесконечном цикле. Кадры считываются из видеопотока методом wrapper.VideoCaptureReadFrame:
empty, err := wrapper.VideoCaptureReadFrame(video)
if err != nil {
fmt.Println(err)
continue
}
if empty {
continue
}
Обнаружение лиц выполняется методом DetectMultiScale с помощью загруженного классификатора:
rects := classifier.DetectMultiScale(*video.Img())
Результаты обнаружения возвращаются в виде прямоугольников rects.
Далее программа вычисляет количество кадров в секунду FPS для вывода на изображение, рисует прямоугольники и текст на изображении.
Если обнаружено лицо, выводится текст Human. Для объектов других классов выводятся названия соответствующих классов.
Если при запуске программы в качестве второго параметра была задана фиксированная частота кадров, выполняется необходимая задержка перед обработкой следующего кадра.
В конце тела цикла программа выводит изображение на экран и ожидает нажатия любой клавиши:
window.IMShow(*video.Img())
if window.WaitKey(1) >= 0 {
break
}
Если нажать клавишу, работа цикла будет прервана.
Исходные тексты библиотеки с обертками wrapper вы найдете в каталоге /root/workspace/ml-repka/wrapper.
Для работы с видео и классификатором в этой библиотеке используются соответствующие методы обертки gocv.io/x/gocv над фреймворком OpenCV.
Программа humandetect #
Программа humandetect использует модель YoloFastestV2 и фреймворк OpenCV. Она составлена на языке программирования C++ (листинг 3). Для сокращения объема статьи полный исходный текст этой программы не приводится.
Листинг 3. ml-repka/humandetect_ncnn_yolofastest_v2/main.cpp
В начале программы определены заголовочные файлы:
#include `opencv2/core/core.hpp`
#include `opencv2/highgui/highgui.hpp`
#include `opencv2/imgproc/imgproc.hpp`
...
#include "yolo-fastestv2.h"
Здесь подключаются заголовочные файлы библиотеки OpenCV, предназначенные для работы с изображениями и видео, заголовочный файл для YOLO, а также заголовочные файлы для работы с потоками ввода-вывода, с функциями для работы с файлами и шаблонный класс динамического массива в стандартной библиотеке C++.
Назначение заголовочных файлов библиотеки OpenCV:
- opencv2/core/core.hpp — основные структуры данных и функции для работы с матрицами, изображениями и массивами в OpenCV;
- opencv2/highgui/highgui.hpp — функции для показа изображений на экране и управления окнами в OpenCV;
- opencv2/imgproc/imgproc.hpp —функции для обработки изображений, такие как фильтрация, преобразование цветовых пространств и обнаружение краев
Документацию на модули OpenCV версии 4.9.0, включая перечисленные выше функции, можно найти здесь.
Для работы с моделью YoloFastestV2 в репозитории ml-repka имеются файлы yolo-fastestv2.cpp (листинг 4) и yolo-fastestv2.h (листинг 5).
Листинг 4. ml-repka/humandetect_ncnn_yolofastest_v2/yolo-fastestv2.cpp
Листинг 5. ml-repka/humandetect_ncnn_yolofastest_v2 yolo-fastestv2.h
В переменной yoloF2 определен объект класса yoloFastestv2:
yoloFastestv2 yoloF2;
При запуске функция main программы humandetect получает два параметра — идентификатор камеры cam_id и количество потоков выполнения num_threads:
int cam_id = atoi(argv[1]);
int num_threads = atoi(argv[2]);
Объект yoloF2 инициализируется следующим образом:
yoloF2.init(false, num_threads); //we have no GPU
После инициализации загружаются файлы предварительно обученной модели:
yoloF2.loadModel("data/yolo-fastestv2-opt.param","data/yolo-fastestv2-opt.bin");
Далее запускается захват видео с камеры при помощи OpenCV:
cv::VideoCapture cap(cam_id);
В рамках бесконечного цикла программа получает кадры видеопотока и запускает обнаружение с помощью метода yoloF2.detection. Далее методы OpenCV рисуют рамку вокруг обнаруженного объекта, а затем выводят на экран изображение с рамками и текстом классов:
while(1){
cap >> frame;
…
std::vector boxes;
yoloF2.detection(frame, boxes);
draw_objects(frame, boxes);
…
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.6, 1.5, &baseLine);
cv::rectangle(frame, cv::Rect(cv::Point(0, 0), cv::Size(label_size.width + 20, label_size.height + 15)), cv::Scalar(0, 0, 0), -1);
putText(frame, text, cv::Point(10, 20), cv::FONT_HERSHEY_SIMPLEX, 0.6, cv::Scalar(0, 255, 0), 1.5);
if (frame.empty()) {
continue;
}
cv::namedWindow("image", cv::WINDOW_NORMAL);
cv::imshow("image", frame);
…
char esc = cv::waitKey(5);
if(esc == 27) break;
}
Цикл будет работать до тех пор, пока пользователь не нажмет какую-нибудь кнопку.
Файлы обученной модели YoloFastestV2 есть в репозитории ml-repka, но их можно скачать и здесь.
Программа сегментации humanseg #
Исходный код сегментации людей humanseg вы найдете в листинге 6.
Листинг 6. ml-repka/humanseg/demo.cpp
Эта программа реализует приложение для сегментации людей в видеопотоке или видеофайле с использованием модели сегментации.
На первом шаге программа получает параметры запуска их командной строки. Путь к файлу обученной модели сегментации human_segmentation_pphumanseg_2023mar.onnx сохраняется в строке modelPath:
string modelPath = parser.get("model");
Далее программа инициализирует модель сегментации, с указанием модели, а также параметров бэкенда и целевого устройства:
PPHS humanSegmentationModel(modelPath, backend_target_pairs[backendTarget].first, backend_target_pairs[backendTarget].second);
Параметры бэкенда определяют, какой движок будет использоваться для выполнения операций инференса (предсказаний) модели. Задавая эти параметры, можно выбрать, где будут выполняться вычисления — на CPU, GPU или на других специализированных аппаратных ускорителях.
После инициализации модели сегментации программа открывает видео поток:
cap.open(samples::findFile(inputPath));
Далее запускается бесконечный цикл обработки кадров видеопотока. В этом цикле программа последовательно захватывает кадры, выполняет инференс модели сегментации и визуализирует результаты.
Захват кадра выполняет следующий код:
cap >> frame;
Инференс модели запускается с изменением времени его выполнения:
tm.start();
result = humanSegmentationModel.infer(frame);
tm.stop();
И, наконец, выполняется визуализация и отображение результата:
Mat res_frame = visualize(frame, result, tm.getFPS());
…
imshow(kWinName, res_frame);
Для завершения цикла нужно нажать любую клавишу в окне отображения.
Полезные ссылки #
- Нейроны и нейромедиаторы
- Аксон
- Дендриты
- Нейромедиатор
- Синапс
- Modelling Microtubules in the Brain as n-qudit Quantum Hopfield Network and Beyond
- Information processing in brain microtubules
- Искусственный нейрон
- Функция активации
- Нейронные сети, перцептрон
- Всё, что вы хотели знать о перцептронах Розенблатта, но боялись спросить
- Машинное обучение. Нейронные сети (часть 1): Процесс обучения персептрона
- Нейрокомпьютерная техника - Алгоритм обучения персептрона
- Алгоритм обучения однослойного персептрона
- Метод коррекции ошибки
- Возможности и ограничения перцептронов
- Сверточная нейронная сеть
- Сверточная нейронная сеть с нуля. Часть 0. Введение
- Свертка и пулинг. Простым языком о компьютерном зрении
- YOLO, SSD и другие
- You Only Look Once: Unified, Real-Time Object Detection
- Что такое регрессия и классификация
- Что такое инференс? Нейрословарь
- Распознавание образов с помощью искусственного интеллекта
- NCNN’S Documentation
- Метод Виолы-Джонса (Viola-Jones) как основа для распознавания лиц
- Haar-like feature
- Документация OpenCV
- Модель YuNet
- Библиотека libfacedetection
- Face detection, attributes, and input data
- Сегментация (обработка изображений)
- Deep learning examples on Raspberry 32/64 OS
- YoloFastestV2 Raspberry Pi 4
Итоги #
Из нашей статьи вы узнали о том, как устроены «живые» нейроны и как их моделируют с помощью компьютеров. Вы познакомились с перцептроном, сверточными сетями, с алгоритмом YOLO и каскадами Хаара.
В практическом плане вы собрали макет на базе микрокомпьютера Repka Pi и веб-камеры, подключенной к Repka Pi через USB, установили Repka OS, Golang, OpenCV, NCNN и репозиторий ml-repka.
Вы научились собирать фреймворки, предназначенное для работы с нейросетями, а также демонстрационные программы из состава репозитория ml-repka.
В статье вы нашли описание исходных текстов программ обнаржуения лиц и людей, а также программы сегментации людей. Мы привели огромное количество ссылок на материалы, с помощью которых вы сможете изучить интереснейшую тему нейросетей подробнее.
На собственном опыте вы смогли убедиться, что микрокомпьютер Repka Pi пригоден для решения таких задач, как обнаружение лиц, людей и других объектов, а также для сегментации людей.
Использованные изображения #
- Nervous Tissue Spinal Cord Motor Neuron
- Complete neuron cell diagram
- Aankomst van Audrey Hepburn en Mel Ferrer op Schiphol, Bestanddeelnr 919-5683
- Olympische spelen, Audrey Hepburn (m) met Oleg Protopopov en Ludmilla Belusova, Bestanddeelnr 921-0655
- Gala-premiere The Unit Story City Amsterdam in aanwezigheid van koningin Juli, Bestanddeelnr 910-7168
- Архитектура сверточной нейронной сети
- Southern Motorway Auckland traffic
- Изображение от Freepik
.jpg){kind=link}
{kind=link}
_met_Oleg_Protopopov_en_Ludmilla_Belusova,_Bestanddeelnr_921-0655.jpg){kind=link}
{kind=link}
{kind=link}
Все, конечно, свалено в одну большую кучу.
1.Разбить бы статью на теорию и практику.
2.Каскады Хаара вынести бы перед yolo, а то складывается впечатление, что это следующий виток эволюции.
3. Непонятно, зачем go устанавливать, если дальше ncnn и c++ используется.
4. Зачем tmp увеличивать для сборки opencv ? Да 6Гб swap многовато для сборки.
5. yolov3 совсем уж древняя.
*Да и не распознавание лиц, а детекция. Распознавание=детекция+идентификация. Это facerecognition, например.
А, так, в целом, хорошо.
Кстати, можно ли csi камеру использовать вместо usb с репкой ? Если да, то какую (какие)?
Да, материал огромен, тут можно разбить даже не на несколько статей, а написать несколько книг. Но в статье много ссылок для более подробного изучения, а сама статья может послужить введением в тему.
Куда интереснее rtsp поток подцепить тогда уж по сети. Интересно Repka Pi4 справится с 10 кадрами в секунду хотя бы HD качества, или ограничения в каждом алгоритме задаются строго?