- Установка Repka OS
- Проверка и настройка микрофона
- Программы распознавания речи на Python
- Программа распознавания речи на C++
- Подведем итоги
В современном мире технологии распознавания речи используются очень широко. Например, они нашли применение в системах управления умным домом, в устройствах IoT, при управлении различным оборудованием, роботехническими игрушками и конечно, в обучающих проектах. Наличие в микрокомпьютере порта GPIO позволяет управлять физическими устройствами голосом.
В этой статье рассказано о том, как настроить локальное (автономно работающее) распознавание речи в реальном времени на микрокомпьютере отечественного Российского производства Repka-Pi 4 Optimal, на борту у которого есть всего 2 Гбайт оперативной памяти. Вскоре ожидается появление Repka Pi 4 Pro с большим количеством оперативной памяти, а так же старшей модели Repka Pi 5 и там будет до 32 Гб ОЗУ. Но пока работаем с тем, что уже есть на рынке на январь 2026 года, да и зачем больше и дороже, если может работать и решать требуемые задачи на имеющемся. Больше памяти нужно если есть необходимость использовать более сложные модели нейронных сетей, это уже отдельный пласт задач, но подход будет тот же самый.
При ограниченных ресурсах приходится использовать модели небольшого объема. В этой статье показано применение модели Vosk с поддержкой русского языка vosk-model-small-ru-0.22. Она «весит» всего 45 Мбайт, что позволяет использовать её на микрокомпьютерах с небольшим объёмом памяти. Конечно, для получения высокого качества распознавания речи лучше использовать модели покрупнее. На момент написания статьи для Vosk это модель vosk-model-ru-0.42 объёмом 1.8 Гбайт. Она предназначена для серверов, но возможно будет удовлетворительно работать и на микрокомпьютере Repka-Pi 5 с большим объёмом оперативной памяти, который, как уже было сказано, на момент написания статьи готовится к производству. Версии моделей Vosk постоянно обновляются. Вы можете отслеживать их на странице моделей.
В статье показано, как настраивать работу с микрофоном, приведёны и разобраны исходники программы распознавания голосовых команд, изменяющих состояние одного из пинов интерфейса GPIO микрокомпьютера. Вы можете подключить к этому пину, например, реле для управления светильником. По команде «лампа» этот светильник будет зажигаться, а по команде «погасить» — выключаться. Разумеется, эти команды можно изменить или добавить новые.
Важно, что для распознавания команд не нужно проводить никакого обучения — заранее обученная нейросеть распознает команды, произнесённые любым разборчивым голосом.
Установка Repka OS #
Скачайте прошивку Repka OS на сайте Repka-Pi и запишите её на карту SD, например, с помощью программы balenaEtcher. Перед включением питания Repka-Pi 4 вставьте карту в соответствующий разъём микрокомпьютера и загрузите Repka OS.
Подключитесь к Repka-Pi как пользователь root и обновите пакеты следующей командой:
sudo apt update
Внимание! Не запускайте после обновления команду apt upgrade!
Для обновления Repka OS используйте программу repka-config (рис. 1).
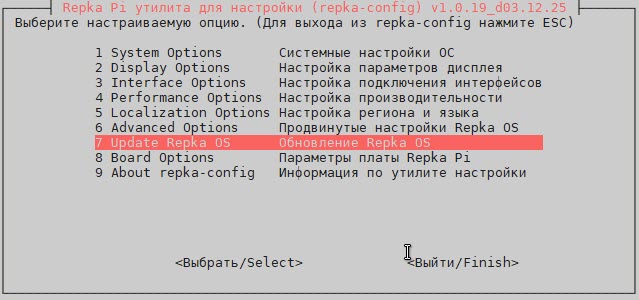
Рис. 1. Обновление Repka OS.
Выполните установку необходимых программ и библиотек:
apt install -y alsa-utils python3 python3-pip g++ portaudio19-dev libasound2-dev
Теперь можно переходить к работе с микрофоном.
Проверка и настройка микрофона #
Качество распознавания речи очень сильно зависит от микрофона и его настроек. Я использовал микрофон, встроенный в Web-камеру Logitech, подключенную к разъёму USB микрокомпьютера Repka-Pi (рис. 2).

Рис. 2. Использован микрофон Web-камеры.
Поиск микрофона #
Прежде всего найдите микрофон и посмотрите его настройки. Для поиска микрофона используйте такую команду:
root@Repka-Pi:~# arecord -l
**** Список CAPTURE устройств ****
карта 0: ac200audio [ac200-audio], устройство 0: 508f000.i2s-ac200-dai ac200-dai-0 [508f000.i2s-ac200-dai ac200-dai-0]
Подустройства: 1/1
Подустройство №0: subdevice #0
карта 2: U0x46d0x825 [USB Device 0x46d:0x825], устройство 0: USB Audio [USB Audio]
Подустройства: 0/1
Подустройство №0: subdevice #0
Микрофон, подключенный к USB, был обнаружен на карте 2, устройство 0.
Тестирование обнаруженного микрофона #
Чтобы проверить найденный микрофон, запустите команду arecord и скажите что-нибудь в микрофон:
arecord -D plughw:2,0 -f S16_LE -r 16000 -c 1 test.wav
Команда выведет на консоль параметры записываемого звукового файла:
Запись WAVE 'test.wav' : Signed 16 bit Little Endian, Частота 16000 Гц, Моно
Для распознавания речи нам потребуется монофонический поток звуковых данных с частотой дискретизации 16000 Гц. Именно такой звуковой файл и будет записан приведённой выше командой.
Параметр -D plughw:2,0 задаёт адрес нашего микрофона — карта 2, устройство 0. Формат данных указывается параметром -f, частота дискретизации параметром -r, а длительность записи в секундах — параметром -c.
После завершения записи прослушайте результат командой aplay:
aplay test.wav
Вы должны услышать четкую и громкую запись.
Настройка уровней записи и воспроизведения #
Если качество записи с микрофона невысокое, запустите программу alsamixer для настройки уровней записи и воспроизведения.
По умолчанию откроется управление встроенным аудиовыходом HDMI (рис. 3).
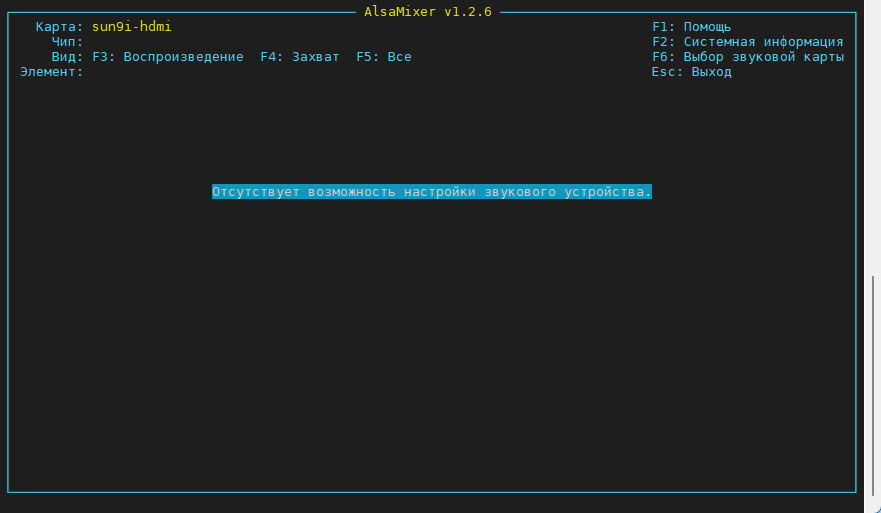
Рис. 3. Первый запуск alsamixer.
Нажмите клавишу F6 и выберите ваше устройство. Я выбрал микрофон, подключенный к USB (рис. 4).
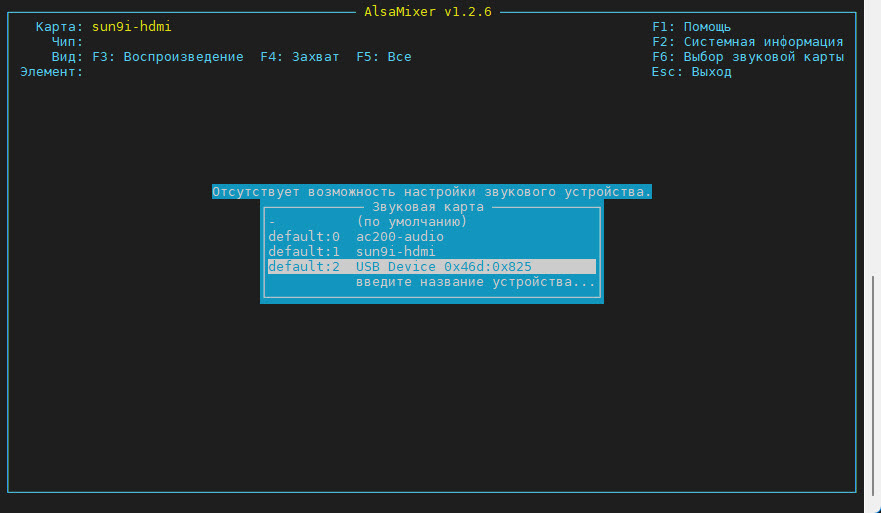
Рис. 4. Выбор нужного микрофона.
После выбора микрофона нажмите клавишу F4, чтобы перейти в режим регулировки усиления (рис. 5).
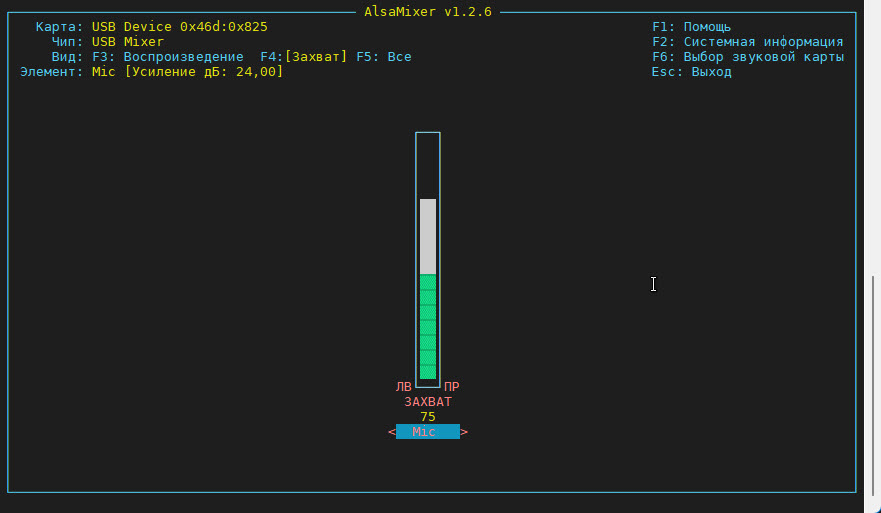
Рис. 5. Режим регулировки уровня усиления микрофона.
Используйте клавиши перемещения курсора Вверх и Вниз для регулировки уровня усиления.
Изменив усиление микрофона, повторите тестовую запись и воспроизведение, как это было описано выше.
Также при необходимость отрегулируйте параметры воспроизведения. Для этого выберите устройство ac200-audio и выполните необходимую регулировку (рис. 6).
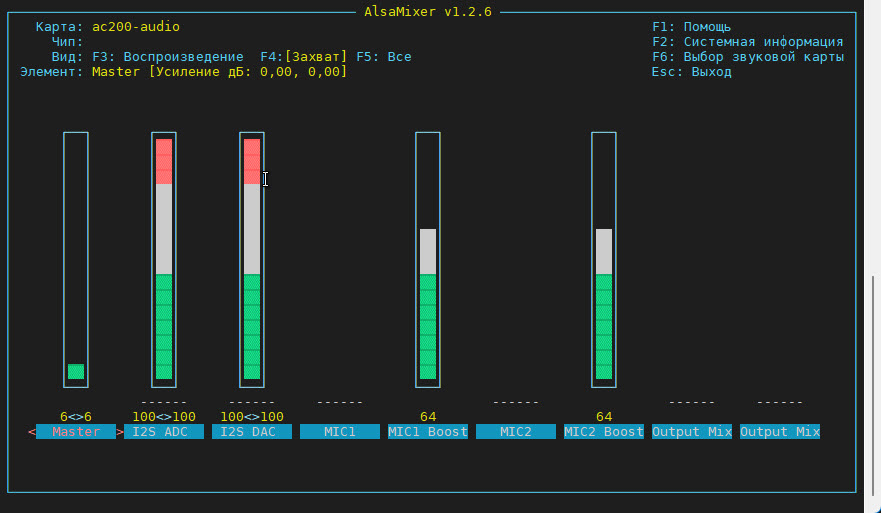
Рис. 6. Регулировка параметров устройства ac200-audio.
Итак, если микрофон работает хорошо, можно переходить к запуску программы распознавания речи.
Программы распознавания речи на Python #
Далее я расскажу о двух программах, первая из которых с названием recognizer.py распознаёт речь в сигнале от микрофона в реальном времени и выводит результаты распознавания на консоль. Вторая программа recognizer-gpio.py управляет голосовыми командами состоянием одного из контактов интерфейса GPIO.
Скачайте программу распознавания речи в реальном времени recognizer.py из репозитория Github и запустите её в консоли на Repka-Pi 4:
# python3 recognizer.py
Программа автоматически определит микрофон, подключенный к разъёму USB микрокомпьютера, и выведет приглашение «Говорите» на экран:
LOG (VoskAPI:ReadDataFiles():model.cc:213) Decoding params beam=10 max-active=3000 lattice-beam=2\
LOG (VoskAPI:ReadDataFiles():model.cc:216) Silence phones 1:2:3:4:5:6:7:8:9:10
LOG (VoskAPI:RemoveOrphanNodes():nnet-nnet.cc:948) Removed 0 orphan nodes.
LOG (VoskAPI:RemoveOrphanComponents():nnet-nnet.cc:847) Removing 0 orphan components.
LOG (VoskAPI:ReadDataFiles():model.cc:248) Loading i-vector extractor from model/ivector/final.ie
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:183) Computing derived variables for iVector extractor
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:204) Done.
LOG (VoskAPI:ReadDataFiles():model.cc:282) Loading HCL and G from model/graph/HCLr.fst model/graph/Gr.fst
LOG (VoskAPI:ReadDataFiles():model.cc:308) Loading winfo model/graph/phones/word_boundary.int
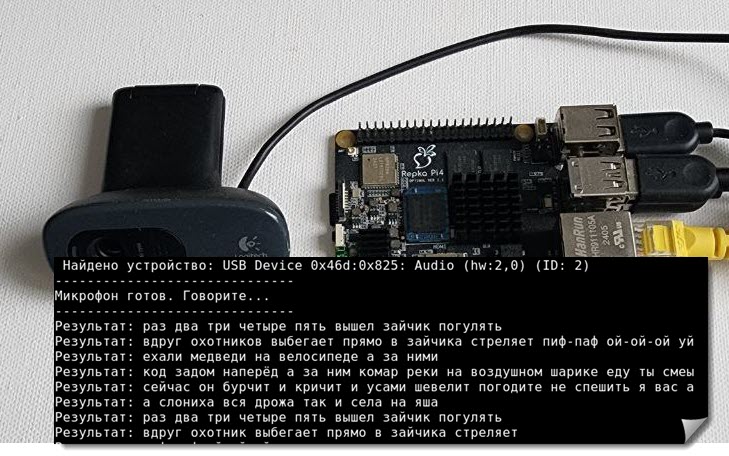
Найдено устройство: USB Device 0x46d:0x825: Audio (hw:2,0) (ID: 2)
------------------------------
Микрофон готов. Говорите...\
Говорите в микрофон с такого расстояния и с такой громкостью как при проведении тестов. Если все сделано правильно, на консоли будут появляться результаты распознавания произнесённых вами слов (рис. 7).
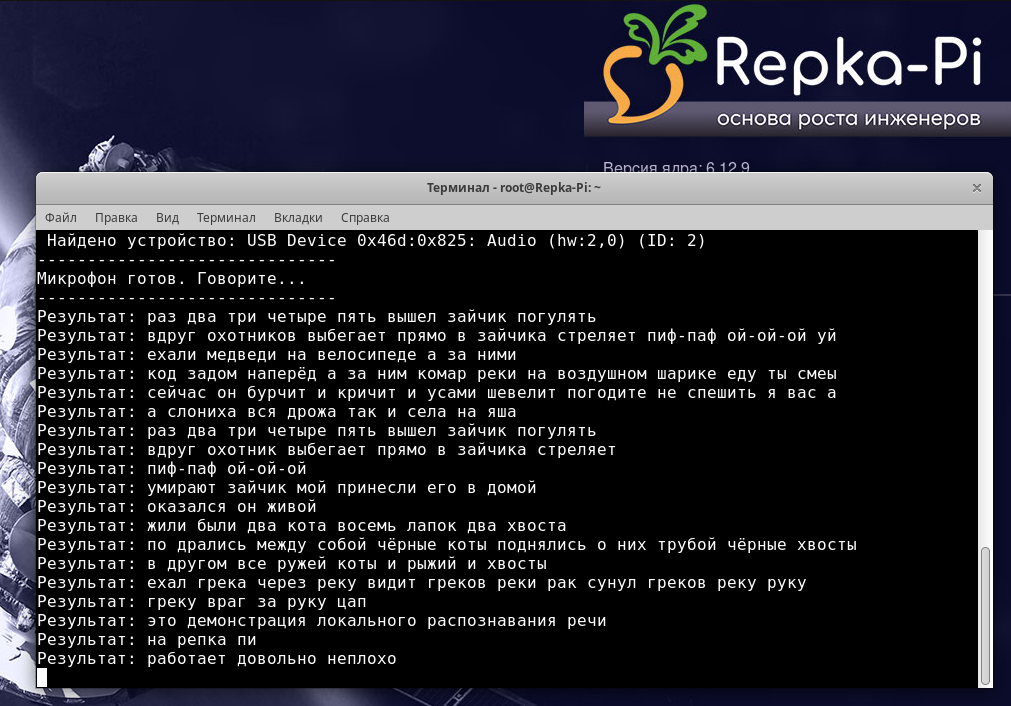
Рис. 7. Распознавание речи с микрофона на Repka-Pi 4.
В целом качество распознавания на такой маленькой модели можно оценить как неплохое.
Исходной код программы recognizer.py #
Расскажу о том, как устроена программа recognizer.py, способная распознавать речь в реальном времени.
В самом начале исходного кода среди прочих импортируются такие библиотеки:
import sounddevice as sd
from vosk import Model, KaldiRecognizer
Библиотека sounddevice нужна для работы с потоком аудио в программах Python. Она может опрашивать список подключенных устройств, выбирать нужное и открывать поток для захвата аудиоданных в режиме реального времени.
Библиотека vosk представляет собой движок распознавания речи, основанный на инструментарии Kaldi.
Из библиотеки vosk импортируется класс Model, содержащий данные о языке, такие как звуки, слова и грамматика. Класс KaldiRecognizer сопоставляет сырые данные от sounddevice с данными из Model, превращая звуки речи в текст.
Получив управление, программа прежде всего проверяет наличие каталога, в который загружена модель:
MODEL_PATH = "model"
if not os.path.exists(MODEL_PATH):
print(f"Ошибка: Папка '{MODEL_PATH}' не найдена.")
exit(1)
Если каталог с файлами модели на месте, программа инициализирует модель. Прежде всего, модель загружается в оперативную память:
model = Model(MODEL_PATH)
Далее создаётся объект «движка» для распознавания речи:
SAMPLE_RATE = 16000
rec = KaldiRecognizer(model, SAMPLE_RATE)
Параметр SAMPLE_RATE задаёт частоту дискретизации, равную 16000 Гц.
Далее программа вызывает функцию find_usb_microphone, задачей которой является получение идентификатора устройства микрофона, подключенного к USB:
device_id = find_usb_microphone()
if device_id is None:
print("USB-микрофон не найден.")
exit(1)
Функция поиска микрофона получает список всех устройств с помощью d.query_devices, и если в названии устройства есть слово «USB» и это устройство ввода, то она возвращает идентификатор найденного микрофона:
def find_usb_microphone():
devices = sd.query_devices()
for i, dev in enumerate(devices):
if 'USB' in dev['name'] and dev['max_input_channels'] > 0:
print(f" Найдено устройство: {dev['name']} (ID: {i})")
return i
return None
Такой подход позволяет обнаруживать микрофон, даже если его идентификатор изменился после перезапуска ОС или после переподключения микрофона.
Если микрофон найден, на консоль выводится приглашение:
print("-" 30)
print("Микрофон готов. Говорите...")
print("-" 30)
На следующем этапе запускается основной цикл программы.
Вначале создаётся поток для передачи «сырых» данных из микрофона в программу. Параметр callback со значением callback задаёт функцию, образующую из этих данных очередь:
with sd.RawInputStream(samplerate=SAMPLE_RATE, blocksize=8000, device=device_id, dtype='int', channels=1, callback=callback):
В главном цикле программа с помощью функции audio_queue.get дожидается получения данных из очереди:
while True:
data = audio_queue.get()
Функция rec.AcceptWaveform анализирует порцию звука, отправляет эту порцию в нейросеть и возвращает значение True, если в речи пользователя появилась пауза:
if rec.AcceptWaveform(data):
result = json.loads(rec.Result())
text = result.get("text", "")
if text:
sys.stdout.write(f"Результат: {text}\n")
sys.stdout.flush()
else:
partial = json.loads(rec.PartialResult())
partial_text = partial.get("partial", "")
if partial_text:
sys.stdout.flush()
В этом случае функция result.get возвращает строку с распознанным текстом, который отображается на консоли.
Когда паузы ещё нет, программа получает черновик распознавания функцией rec.PartialResult и тоже выводит её на консоль.
Программа голосового управления GPIO #
Для демонстрации возможности голосового управления оборудованием при помощи распознавания речи на микрокомпьютере Repka-Pi я подготовил программу recognizer-gpio.py. Она представляет собой изменённый вариант рассмотренной выше программы recognizer.py.
Программа recognizer-gpio.py анализирует распознанный текст и ищет в нём слова команд «лампа» и «погасить». Первая из этих команд устанавливает состояние 1 на физическом контакте 7 порта GPIO (GPIO04), а вторая — сбрасывает его в 0.
Сразу после запуска программы, а также после получения команды «погасить» на выходе контакта 7 устанавливается нулевое напряжение. Подключенный к этому контакту светодиод не горит (рис. 8).

Рис. 8. Светодиод выключен.
После получения команды «лампа» на контакте 7 устанавливается напряжение 3.3 В и светодиод загорается (рис. 9).

Рис. 9. Светодиод загорелся.
Подключив к этому контакту реле, можно управлять реальным светильником. На рис. 10 показано управление светодиодом через реле.

Рис. 10. Управление светодиодом через реле.
Выводы реле DC+ и DC- подключены, соответственно, к +5 В (физический контакт 2 микрокомпьютера Repka Pi) и к земле (физический контакт 6).
Сигнал управления подается на контакт IN4 реле (четвертое реле из блока) с физического контакта 7 микрокомпьютера.
Нормально разомкнутые контакты ТС4 и COM4 четвёртого реле подключены к светодиоду и источнику питания 5 В через резистор 1 КОм.
Разумеется, вы можете подключить к реле более серьёзную нагрузку, чем светодиод. В интернете есть даташит на реле, установленные в этом блоке. Там вы найдёте предельные значения напряжения и тока, которые может коммутировать такое реле.
В процессе распознавания и выполнения команд программа recognizer-gpio.py выводит сообщения о своих действиях на консоль (рис. 11).
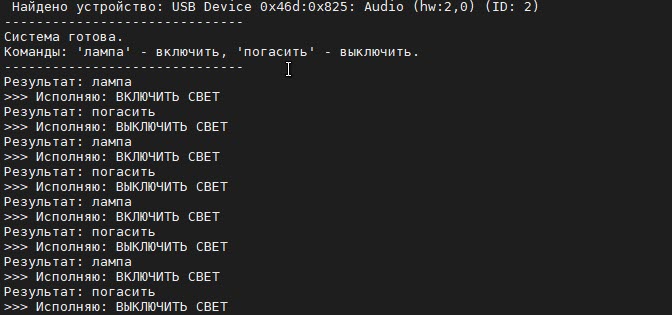
Рис. 11. Вывод сообщений о действиях на консоль.
Теперь я расскажу, чем программа recognizer-gpio.py отличается от recognizer.py. Главное отличие заключается в добавлении кода управления портом GPIO и кодом обнаружения команд в распознанном тексте.
Для управления состоянием пинов порта GPIO используется модуль RepkaPi.GPIO:
import RepkaPi.GPIO as GPIO
Этот модуль описан в статье «Первые шаги: Моргаем светодиодом на python с помощью библиотеки RepkaPi.GPIO SysFS».
Я использовал для наглядности физическую нумерацию контактов GPIO на плате микрокомпьютера. Здесь я задал для управления контакт с номером 7:
LED_PIN = 7
Далее программа выполняет инициализацию и выключает напряжение на контакте 7:
GPIO.setmode(GPIO.BOARD)
GPIO.setup(LED_PIN, GPIO.OUT)
GPIO.output(LED_PIN, GPIO.LOW)
После запуска программа выводит на консоль команды управления нашим контактом:
print("-" 30)
print("Система готова.")
print("Команды: 'лампа' - включить, 'погасить' - выключить.")
print("-" 30)
Логика управления при помощи команд реализована в главном цикле программы:
while True:
data = audio_queue.get()
if rec.AcceptWaveform(data):
result_json = json.loads(rec.Result())
text = result_json.get("text", "").lower()
if text:
print(f"Результат: {text}")
if "лампа" in text:
print(">>> Исполняю: ВКЛЮЧИТЬ СВЕТ")
GPIO.output(LED_PIN, GPIO.HIGH)
elif "погасить" in text:
print(">>> Исполняю: ВЫКЛЮЧИТЬ СВЕТ")
GPIO.output(LED_PIN, GPIO.LOW)
else:
# Промежуточный результат (динамическое отображение)
partial = json.loads(rec.PartialResult())
partial_text = partial.get("partial", "")
if partial_text:
sys.stdout.write(f"\r Слушаю: {partial_text}...\033[K")
sys.stdout.flush()
В процессе анализа этот код переводит полученный текст в нижний регистр для надёжности. Получив текст, программа выводит его на консоль и смотрит, содержит ли этот текст слова команд «лампа» и «погасить».
Если обнаружено слово «лампа», программа устанавливает на контакте 7 состояние единицы (напряжение 3.3 В):
GPIO.output(LED_PIN, GPIO.HIGH)
При этом зажигается светодиод или лампа, подключенная к контакту 7.
При обнаружении внутри строки распознанного текста слова «погасить» программа устанавливает на контакте 7 состояние нуля (напряжение 0 В):
GPIO.output(LED_PIN, GPIO.LOW)
Перед завершением своей работы программа сбрасывает порт GPIO в начальное состояние:
GPIO.output(LED_PIN, GPIO.LOW)
GPIO.cleanup()
Полный исходный текст программы recognizer-gpio.py есть в моём репозитории на Github.
Программа распознавания речи на C++ #
Учитывая, что многие программы для встраиваемых систем разрабатывают на C++, я подготовил для Repka-Pi 4 программу распознавания речи на языке C++. Далее я приведу описание программы, а также расскажу о том, как её собрать и запустить.
Описание программы #
В самом начале программы подключаются все необходимые библиотеки:
#include <iostream>
#include <vector>
#include <string>
#include <cstring>
#include <portaudio.h>
#include "vosk_api.h"
Библиотека iostream нужна для вывода данных в консоль.
С помощью библиотеки vector программа создаёт контейнер для временного хранения фрагментов записанного звука.
Для разбора JSON-ответов нейросети и поиска нужного микрофона в списке устройств программа использует библиотеки string и cstring. А вот общение с микрофоном выполняет библиотека захвата звука portaudio.h.
И, наконец, библиотека vosk_api.h предоставляет доступ к API уже знакомой вам библиотеке Vosk.
Макрос CHECK_PA_ERROR нужен для проверки ошибок PortAudio и корректного завершения работы программы при обнаружении таких ошибок:
#define CHECK_PA_ERROR(err) if(err != paNoError && err != paInputOverflowed) { \
std::cerr << "PortAudio error: " << Pa_GetErrorText(err) << std::endl; \
return -1; \
}
В программе используется функция print_recognized_text, предназначенная для безопасного извлечения текста из JSON строки Vosk:
void print_recognized_text(const char* json_raw) {
std::string res = json_raw;
std::string key = "\"text\" : \"";
size_t startPos = res.find(key);
if (startPos != std::string::npos) {
startPos += key.length();
size_t endPos = res.find("\"", startPos);
if (endPos != std::string::npos) {
std::string text = res.substr(startPos, endPos - startPos);
if (!text.empty()) {
std::cout << "\r>>> РАСПОЗНАНО: " << text << std::endl;
}
}
}
}
В самом начале функции main выполняется инициализация vosk и загрузка модели:
int main() {
VoskModel model = vosk_model_new("model");
if (!model) {
std::cerr << "ОШИБКА: Не удалось загрузить модель из папки 'model'!" << std::endl;
return -1;
}
VoskRecognizer recognizer = vosk_recognizer_new(model, SAMPLE_RATE);
Далее программа сканирует устройства ввода, в названии которых есть слова «USB» или «Audio»:
CHECK_PA_ERROR(Pa_Initialize());
int numDevices = Pa_GetDeviceCount();
int inputDevice = -1;
for (int i = 0; i < numDevices; i++) {
const PaDeviceInfo* deviceInfo = Pa_GetDeviceInfo(i);
if (deviceInfo->maxInputChannels > 0 && (strstr(deviceInfo->name, "USB") || strstr(deviceInfo->name, "Audio"))) {
std::cout << "Найдено устройство: " << deviceInfo->name << " (ID: " << i << ")" << std::endl;
inputDevice = i;
break;
}
}
Если микрофон найти не удалось, для ввода используется системный вход аудио:
if (inputDevice == -1) {
std::cout << "USB микрофон не найден, использую стандартный вход." << std::endl;
inputDevice = Pa_GetDefaultInputDevice();
}
На следующем этапе программа задаёт настройки для библиотеки PortAudio:
PaStreamParameters inputParameters;
inputParameters.device = inputDevice;
inputParameters.channelCount = 1;
inputParameters.sampleFormat = paInt16;
inputParameters.suggestedLatency = Pa_GetDeviceInfo(inputParameters.device)->defaultHighInputLatency;
inputParameters.hostApiSpecificStreamInfo = NULL;
Здесь указывается:
- идентификатор обнаруженного микрофона inputParameters.device;
- монофонический режим inputParameters.channelCount;
- разрядность звуковых данных inputParameters.sampleFormat (целые 16-битные числа);
- задержку по умолчанию для устройства;
- поле специфических настроек inputParameters.hostApiSpecificStreamInfo для конкретных типов ОС
На следующем этапе программа поток с помощью функции Pa_OpenStream выводит на консоль приглашение для начала процесса распознавания речи с микрофона:
PaStream *stream;
CHECK_PA_ERROR(Pa_OpenStream(&stream, &inputParameters, NULL, SAMPLE_RATE, FRAMES_PER_BUFFER, paClipOff, NULL, NULL));
CHECK_PA_ERROR(Pa_StartStream(stream));
std::cout << "\n--- СИСТЕМА ГОТОВА. ГОВОРИТЕ... (Ctrl+C для выхода) ---\n" << std::endl;
Ниже я привёл описание параметров функции Pa_OpenStream:
- &stream — указатель созданный поток;
- &inputParameters — указатель на настройки для библиотеки PortAudio;
- NULL — параметры для выхода, не используются;
- SAMPLE_RATE — частота дискретизации 16000 Гц;
- FRAMES_PER_BUFFER — размер звукового фрагмента (2048 фреймов) для обработки за один раз;
- paClipOff — флаг, отключающий автоматическое ограничение амплитуды (клиппинг), чтобы данные поступали в нейросеть «как есть»;
- NULL, NULL — параметры, задающие Callback-функции для обработки звука в реальном времени. Наша программа использует метод прямого чтения из буфера, поэтому они не нужны
В буфере buffer находится временное хранилище образцов звука:
std::vector buffer(FRAMES_PER_BUFFER);
Далее программа запускает основной цикл обработки:
while (true) {
PaError err = Pa_ReadStream(stream, buffer.data(), FRAMES_PER_BUFFER);
if (err != paNoError && err != paInputOverflowed) {
std::cerr << "Критическая ошибка аудио: " << Pa_GetErrorText(err) << std::endl;
break;
}
int is_final = vosk_recognizer_accept_waveform_s(recognizer, buffer.data(), FRAMES_PER_BUFFER);
if (is_final) {
print_recognized_text(vosk_recognizer_result(recognizer));
}
}
Здесь программа читает аудиоданные функцией Pa_ReadStream и передаёт их в нейросеть, вызывая функцию vosk_recognizer_accept_waveform_s.
Если эта функция определила конец фразы (по паузе), данные выводятся на консоль функцией print_recognized_text.
Если пользователь прерывает выполнение программы, нажав комбинацию клавиш Ctrl+C, программа выполняет очистку и завершает свою работу:
Pa_StopStream(stream);
Pa_CloseStream(stream);
Pa_Terminate();
vosk_recognizer_free(recognizer);
vosk_model_free(model);
return 0;
В этом фрагменте кода функция Pa_StopStream прекращает захват звука, функция Pa_CloseStream удаляет объект потока и очищает буферы драйвера, а функция Pa_Terminate полностью выгружает библиотеку PortAudio из памяти.
Освобождение ресурсов vosk выполняют функции vosk_recognizer_free и vosk_model_free. Первая из них удаляет экземпляр распознавателя, а вторая — выгружает нейросетевую модель из оперативной памяти.
Сборка и запуск программы #
Перед сборкой установите необходимые зависимости:
apt install -y g++ portaudio19-dev libasound2-dev
Создайте каталог asr-cpp для сборки программы и сделайте его текущим:
mkdir asr-cpp
cd asr-cpp
Загрузите и распакуйте библиотеку vosk-linux-aarch64-0.3.45.zip:
wget https://github.com/alphacep/vosk-api/releases/download/v0.3.45/vosk-linux-aarch64-0.3.45.zip
unzip vosk-linux-aarch64-0.3.45.zip
Перенесите результаты распаковки в каталог libvosk и запустите сборку программы:
mv vosk-linux-aarch64-0.3.45 libvosk
g++ main.cpp -I./libvosk -L./libvosk -lvosk -lportaudio -o speech_rec
Запуск программы выполните с помощью следующих команд:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$(pwd)/libvosk
./speech_rec
После запуска на консоли появится множество сообщений об ошибках от ALSA, которые вы можете игнорировать:
root@Repka-Pi:~/asr-cpp# ./speech_rec
LOG (VoskAPI:ReadDataFiles():model.cc:213) Decoding params beam=10 max-active=3000 lattice-beam=2
LOG (VoskAPI:ReadDataFiles():model.cc:216) Silence phones 1:2:3:4:5:6:7:8:9:10
LOG (VoskAPI:RemoveOrphanNodes():nnet-nnet.cc:948) Removed 0 orphan nodes.
LOG (VoskAPI:RemoveOrphanComponents():nnet-nnet.cc:847) Removing 0 orphan components.
LOG (VoskAPI:ReadDataFiles():model.cc:248) Loading i-vector extractor from model/ivector/final.ie
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:183) Computing derived variables for iVector extractor
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:204) Done.
LOG (VoskAPI:ReadDataFiles():model.cc:282) Loading HCL and G from model/graph/HCLr.fst model/graph/Gr.fst
LOG (VoskAPI:ReadDataFiles():model.cc:308) Loading winfo model/graph/phones/word_boundary.int
ALSA lib confmisc.c:1369:(snd_func_refer) Unable to find definition 'cards.1.pcm.front.0:CARD=1'
ALSA lib conf.c:5178:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5701:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2664:(snd_pcm_open_noupdate) Unknown PCM front
ALSA lib pcm.c:2664:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.rear
ALSA lib pcm.c:2664:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.center_lfe
ALSA lib pcm.c:2664:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.side
ALSA lib confmisc.c:1369:(snd_func_refer) Unable to find definition 'cards.1.pcm.surround51.0:CARD=1'
ALSA lib conf.c:5178:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5701:(snd_config_expand) Evaluate error: No such file or directory
snd_func_refer returned error: No such file or directory
Эти сообщения возникают в процессе опроса устройств с целью поиска микрофона. Не все эти устройства существуют, отсюда и ошибки.
Когда микрофон будет обнаружен, на экране появится приглашение и результаты распознавания текста:
Найдено устройство: USB Device 0x46d:0x825: Audio (hw:2,0) (ID: 2)
--- СИСТЕМА ГОТОВА. ГОВОРИТЕ... (Ctrl+C для выхода) ---
>>> РАСПОЗНАНО: раз два три четыре пять
>>> РАСПОЗНАНО: вышел зайчик погулять
>>> РАСПОЗНАНО: ехали медведи на велосипеде
Подведем итоги #
Микрокомпьютер Repka Pi 4 вполне пригоден для распознавания речи. Причём не только как агент, передающий звук от микрофона на сервер с GPU, но и для локального распознавания в реальном времени. Из-за небольшого объёма оперативной памяти, установленной на Repka Pi 4, приходится использовать самую маленькую модель Vosk. Но и такая модель показала хорошие результаты для русского языка. Можно предположить, что следующая модель Repka-Pi 5, которая уже готовится к производству, позволит использовать большие модели. Это обеспечит более качественное распознавание.
Используя Repka-Pi 4 и Vosk, уже сейчас можно создавать локальные системы голосового управления различными устройствами, подключенными к порту GPIO микрокомпьютера.
Используя реле и оборудование, подключенное через контакты GPIO, через I2C и UART можно выдавать команды на самое разнообразное оборудование. Например, можно организовать голосовое управление умным домом, станками и тому подобными устройствами.
Следует также заметить, что качество распознавания в большой степени зависит от микрофона. Сейчас в продаже есть активные микрофоны, оборудованные системами автоматической регулировкой усиления, настраиваемыми фильтрами и эквалайзерами, позволяющими оптимизировать звук для распознавания.
Если Вам нравятся подобные эксперименты с распознаванием речи на Repka-Pi 4, пишите в отзывах, о чём вам было бы ещё интересно узнать по этой теме.