- Краткая история синтезаторов речи
- “Старый” способ - Программа eSpeak NG
- Используем нейросеть - Синтезатор речи Piper TTS
- Сервер синтеза речи на базе Piper и Repka-Pi 4
- Итоги
Несмотря на ограниченные ресурсы, современные микрокомпьютеры вполне могут синтезировать речь с приемлемым качеством, используя технологии нейросетей. В этой статье я расскажу о том, как добавить «голос» к микрокомпьютеру отечественной сборки Repka-Pi 4.
Я буду использовать программные синтезаторы речи (TTS, Text-to-Speech) eSpeak NG и Piper, показавшие неплохие результаты на Repka-Pi 4.
Вы сможете использовать приведённые в статье коды сервера синтезатора речи, созданного на базе Piper и FastAPI. Этот сервер запускается через systemd автоматически при включении питания Repka-Pi и получает запросы на синтез речи от внешних клиентов через HTTP. Получив такой запрос, сервер ставит его в очередь на «озвучивание». При этом клиент может не дожидаться окончания синтеза, а продолжать свою работу.
Скоро в продаже появится более мощный микрокомпьютер Repka-Pi 5 с большим объемом оперативной памяти, быстрым процессором и памятью. На ней синтез речи будет выполняться быстрее и эффективнее, можно будет использовать более крупные модели. Но и Repka-Pi 4 вполне может быть использована, например, в системах умного дома, киосках, говорящих умных игрушках, а также в учебных проектах.
Краткая история синтезаторов речи #
Прежде чем перейти к практике, я кратко расскажу об истории развития технологий синтеза речи, от первых механических синтезаторов до применения нейросетей.
Механические синтезаторы речи #
Первые попытки синтеза речи были предприняты еще в конце XVIII века. Для примера на рис. 1 показана копия говорящей машины Фабера, созданная в 1846 году.

Рис. 1. Механический синтезатор (источник)
{kind=link}
При помощи ножной педали и воздушного меха в устройство подавался воздух. Для имитации человеческого органа речи изобретатель установил в надставной трубе своей машины вертикально одну за другой шесть металлических диафрагм, подымающихся и опускающихся на различную высоту.
Комбинируя при помощи пальцев расположение этих диафрагм, а также форму надставной трубы, можно было получать звуки различного тембра, напоминающие человеческую речь.
Другой пример — Euphonia Иосифа Фабера. Это гибрид механического синтезатора речи на основе акустических устройств и клавиш, созданный в 1845–1846 годах (рис. 2).

Рис. 2. Механический синтезатор речи Euphonia Иосифа Фабера (источник)
Конечно, качество «речи», полученной от механических синтезаторов, для практического применения было очень низким. Однако такие синтезаторы смогли продемонстрировать саму идею синтеза речи.
Электронные синтезаторы речи #
Следующий этап развития синтезаторов речи был связан с применением электроники. В 1930 году Хомер Дадли из Bell Telephone Laboratories создан электронный синтезатор речи Voder (voice operating demonstrator). Схема его работы показана на рис. 3.
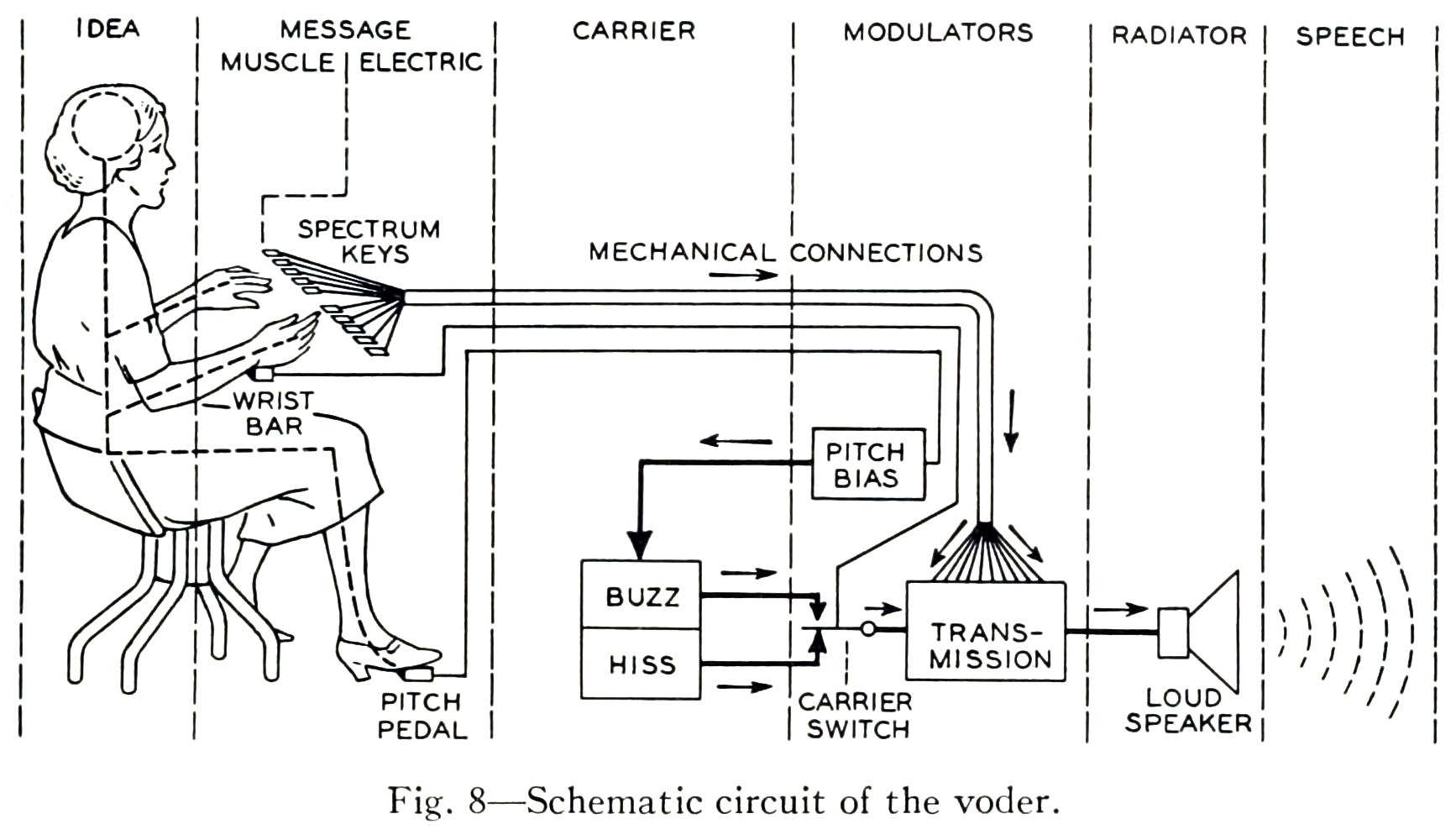
Рис. 3. Электронный синтезатор речи Voder (источник)
Для синтеза речи здесь использовались клавиши, педаль, генераторы тона и шума, а также фильтры.
Среди других электронных синтезаторов можно упомянуть Pattern playback, созданный Haskins Labs в 1940-1950 годы. Это устройство создавало звук из спектрограмм речи.
Синтез речи с помощью компьютеров #
Когда наступила эра компьютеров, их сразу же попытались применить для синтеза речи.
В 1961 году в Bell Labs для синтеза слов песни Daisy Bell сделали моделирование речевого тракта на программном уровне. При этом был использован компьютер IBM 704.
В 1968 году в японской лаборатории Electrotechnical Laboratory была создана первая система программного синтезатора речи TTS. В нём применялся формантный синтез на основе правил фонетической транскрипции.
Также можно упомянуть систему MUSA (1975-1978 годы). Это была одна из первых систем синтеза речи в реальном времени. Она «говорила» на итальянском языке, но речь была больше похожа на голос робота.
В период с 1980 по 1990 годы велись разработки синтезаторов на основе формантного синтеза с лингвистическим анализом текста, а также с использованием детализированных фонем и правил для генерации речи.
Начиная с 1990 года в синтезаторах речи стали применяться статистические методы. Однако действительно высококачественный синтез речи стал возможен только с применением нейросетей.
Подробнее об использовании нейросетей для синтеза речи читайте в статье «Что такое технология TTS, как устроена и каких сферах используется синтез речи». Об истории создания синтезаторов речи можно прочитать в статье «A History of Text-to-Speech: From Mechanical Voices to AI Assistants».
Программа eSpeak NG #
Если вы ищите легковесный синтезатор речи для микрокомпьютера и вам не так уж важно качество речи, то можно испытать программный синтезатор речи eSpeak NG. Это проект с открытыми исходными кодами (Open Source), использующий метод формантного синтеза.
Не вдаваясь в подробности, скажу, что при использовании этого метода голос генерируется алгоритмически, без записи реальных голосов. В результате будет создан «голос робота», который звучит неестественно.
Из преимуществ eSpeak NG можно отметить нетребовательность к ресурсам компьютера, что позволяет запускать этот синтезатор на Repka-Pi 4 с объёмом памяти всего 2 ГБайта.
Вы можете использовать eSpeak NG, например, для чтения уведомлений, в учебных и других проектах, где нет особых требований к качеству речи.
Установка eSpeak NG #
Процесс установки eSpeak NG несложен. Нужно обновить пакеты и запустить процесс установки:
apt update
apt install espeak-ng
После установки проверьте, доступен ли русский язык:
espeak-ng --voices | grep Russian
5 ru --/M Russian zle/ru
2 ru-lv --/M Russian_(Latvia) zle/ru-LV
Запуск eSpeak NG из командной строки #
Для запуска eSpeak NG используйте командную строку:
espeak-ng "Привет Репка Пи" -v ru
Или на английском языке:
espeak-ng "Hello Repka pi" -v en
Вы можете запустить синтез из большого текста через командную строку:
espeak -v ru -s 150 << EOF
Привет мир!
Это очень длинный текст,
который занимает несколько строк.
Здесь может быть абзац,
ещё один абзац,
и даже диалог:
— Привет!
— Здравствуй, Репка-Пи!
EOF
Если нужно произнести текст, записанный в файл, воспользуйтесь такой командой:
espeak-ng -v ru -s 150 -f hello-repka-pi.txt
В параметре -v можно задать разные голоса:
- ru — стандартный русский;
- ru+m1 … m7 — разные мужские русские голоса;
- ru+f1 … f5 — разные женские русские голоса
Например, так можно выбрать женский голос f5:
espeak-ng -v ru+f5 -s 150 -f hello-repka-pi.txt
Запуск eSpeak NG из программы Python #
Ниже я привёл программу на Python espeak-ng-test.py (есть в моём репозитории Github), запускающую синтез речи с помощью espeak-ng:
import subprocess
def say(text, voice="ru", speed=150, pitch=50):
"""
Параметры:
voice — голос/язык (ru, en, de, fr, ro и т.д.)
speed — скорость (обычно 80–200)
pitch — высота голоса (0–99)
"""
try:
subprocess.run([
"espeak-ng",
"-v", voice,
"-s", str(speed),
"-p", str(pitch),
text
], check=True, capture_output=True)
except FileNotFoundError:
print("espeak-ng не найден. Установите его:")
print(" sudo apt install espeak-ng")
except subprocess.CalledProcessError as e:
print("Ошибка espeak-ng:", e.stderr.decode())
if name == "_main_":
say("Привет! Это проверка русского голоса.", voice="ru", speed=140)
say("Hello, this is a test in English", voice="en-us", speed=160, pitch=60)
say("Тестируем другой русский голос", voice="ru+f3", speed=135)
Здесь тестируются два голоса для русского языка и один для английского.
Для запуска программы используйте команду:
python3 espeak-ng-test.py
Синтезатор речи Piper TTS #
Меня совсем не впечатлило качество звука, синтезированного при помощи eSpeak NG. Да, звук появляется в колонках практически сразу после запуска, но по моим ощущениям это голос робота из 80-х.
Намного лучше получилась речь, синтезированная локальным нейросетевым синтезатором речи Piper TTS. Этот синтезатор вполне работоспособен на микрокомпьютере Repka-Pi 4.
Хорошее качество речи достигается обучением по архитектуре вариационного вывода с использованием состязательного обучения для сквозного преобразования текста в речь VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech). При этом применяются модели, экспортированные в формат ONNX.
За счёт применения ONNX и облегчённых моделей возможно выполнение синтеза в реальном времени на микрокомпьютерах. Это позволяет применять Piper TTS для голосовых ассистентов, умных устройств, роботов, информационных проектов, а также в учебных проектах на Repka-Pi.
Установка Piper TTS #
Установку Piper TTS можно выполнить в виртуальном окружении:
sudo apt update
sudo apt install python3-pip
python3 -m venv ~/piper_env
source ~/piper_env/bin/activate
pip install --upgrade pip
pip install piper-tts sounddevice numpy
Далее нужно скачать голоса:
mkdir -p ~/piper-voices/ru
cd ~/piper-voices/ru
wget https://huggingface.co/rhasspy/piper-voices/resolve/v1.0.0/ru/ru_RU/denis/medium/ru_RU-denis-medium.onnx?download=true -O ru_RU-denis-medium.onnx
wget https://huggingface.co/rhasspy/piper-voices/resolve/v1.0.0/ru/ru_RU/denis/medium/ru_RU-denis-medium.onnx.json?download=true -O ru_RU-denis-medium.onnx.json
Ссылки на другие голоса для Piper можно найти на сайте huggingface.co.
Запуск Piper TTS из командной строки #
Для проверки качества синтеза используйте такую команду:
piper --model ~/piper-voices/ru/ru_RU-irina-medium.onnx \
--output_file большой_текст.wav <<EOF
Привет мир!
Это очень длинный текст,
который занимает несколько строк.
Здесь может быть абзац,
ещё один абзац,
и даже диалог:
— Привет!
— Здравствуй, Репка-Пи!
EOF
Здесь синтезированная речь будет записана в звуковой файл большой_текст.wav, котрый затем можно будет проиграть с помощью программы aplay:
aplay большой_текст.wav
Если нужно прочитать голосом текст из файла, используйте такую команду:
piper \
--model ~/piper-voices/ru/ru_RU-irina-medium.onnx \
--output_raw \
< hello-repka-pi.txt \
| aplay -r 22050 -f S16_LE -t raw -D pulse
В данном случае звуковой файл не создаётся — результаты синтеза сразу отправляются программе aplay.
Сообщение, показанное ниже, говорит о том, что не обнаружен GPU:
2026-01-29 11:35:29.132001366 [W:onnxruntime:Default, device_discovery.cc:164 DiscoverDevicesForPlatform] GPU device discovery failed: device_discovery.cc:89 ReadFileContents Failed to open file: "/sys/class/drm/card1/device/vendor"
Действительно, микрокомпьютер Repka-Pi 4 не оборудован GPU. Вы можете игнорировать это сообщение.
Также при запуске команды синтеза без формирования звукового файла на консоли может появится такое сообщение:
недобор!!! (не менее 1464,249 мс длинной)
Оно возникает из-за того, что процессор не успевает готовить аудиоданные достаточно быстро. На более производительном микрокомпьютере Repka-Pi 5, который скоро будет доступен такое сообщение может не появляться.
В любом случае качество звука и на Repka-Pi 4 получается вполне удовлетворительным.
Запуск Piper TTS из программы Python #
Синтезатор речи Piper TTS можно запускать из программ, составленных на Python. Для запуска программ, которые я привёл в статье, установите необходимые зависимости:
sudo apt update
sudo apt install -y libportaudio2 portaudio19-dev python3-pyaudio
pip install pyaudio
Первая программа piper_stream_aplay.py проигрывает синтезированную речь через утилиту aplay без создания промежуточного wav-файла на диске.
В начале программы задаются такие параметры, как путь к исполнимому файлу Piper, к модели ONNX, частота дискретизации, формат создаваемого звука и устройство вывода:
PIPER_BIN = "piper" # путь к программе Piper
MODEL_PATH = "/root/piper-voices/ru/ru_RU-irina-medium.onnx"
SAMPLE_RATE = "22050"
FORMAT = "S16_LE" # 16 бит со знаком little-endian
DEVICE = "pulse" # можно поменять на hw:0,0 и так далее
Функция main проверяет передан ли путь к файлу с текстом, и если передан, то вызывает функцию speak_from_file:
def main():
if len(sys.argv) != 2:
print(
f"Использование:\n"
f" {sys.argv[0]} <путь_к_текстовому_файлу>",
file=sys.stderr
)
sys.exit(1)
text_file = Path(sys.argv[1])
speak_from_file(text_file)
В свою очередь, функция speak_from_file выполняет весь цикл синтеза речи.
Первым делом функция проверяет наличие файла, и если файл есть, читает его в переменную text, убирая пробелы в начале и в конце текста:
if not text_path.exists():
print(f"❌ Файл не найден: {text_path}", file=sys.stderr)
sys.exit(1)
text = text_path.read_text(encoding="utf-8").strip()
if not text:
print("❌ Файл пустой", file=sys.stderr)
sys.exit(1)
Далее функция запускает Piper в режиме потока:
piper = subprocess.Popen(
[
PIPER_BIN,
"--model", MODEL_PATH,
"--output_raw"
],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL
)
Параметр --output_raw указывает, что нужно выдать сырой PCM, а не wav-файл. Параметры stdin и stdout нужны для получения текста и выдачи данных аудио, соответственно.
На следующем шаге функция запускает процесс aplay для воспроизведения звука:
aplay = subprocess.Popen(
[
"aplay",
"-r", SAMPLE_RATE,
"-f", FORMAT,
"-t", "raw",
"-D", DEVICE
],
stdin=piper.stdout,
stderr=subprocess.DEVNULL
)
Это аналогично запуску команды:
aplay -r 22050 -f S16_LE -t raw -D pulse
Программа aplay получает сырые данные в формате PCM с частотой 22050 Гц из потока piper.stdout.
Перед завершением своей работы функция speak_from_file передаёт текст в piper.stdin и ждёт завершения обоих процессов:
piper.stdin.write(text.encode("utf-8"))
piper.stdin.close()
aplay.wait()
piper.wait()
Запустить эту программу можно так:
python3 piper_stream_aplay.py hello-repka-pi.txt
Здесь я передаю ей в качестве параметра путь к файлу hello-repka-pi.txt с текстом, для которого нужно синтезировать речь.
Ещё одна программа piper-stream.py передаёт результаты синтеза текста сразу в звуковое устройство (колонки, подключенные к Repka-Pi). Она воспроизводит через библиотеку sounddevice, минуя запуск внешних программ.
Основные отличия здесь в функции speak_from_file:
def speak_from_file(text_path: Path):
if not text_path.exists():
print(f" Файл не найден: {text_path}", file=sys.stderr)
sys.exit(1)
text = text_path.read_text(encoding="utf-8").strip()
if not text:
print(" Файл пустой", file=sys.stderr)
sys.exit(1)
sd.default.device = "pulse"
sd.default.samplerate = SAMPLE_RATE
sd.default.channels = CHANNELS
proc = subprocess.Popen(
[
PIPER_BIN,
"--model", MODEL,
"--output_raw"
],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL
)
proc.stdin.write(text.encode("utf-8"))
proc.stdin.close()
with sd.RawOutputStream(
samplerate=SAMPLE_RATE,
channels=CHANNELS,
dtype=DTYPE,
blocksize=BLOCKSIZE,
latency="high"
) as stream:
stream.start()
while True:
data = proc.stdout.read(BLOCKSIZE BYTES_PER_SAMPLE 2)
if not data:
break
# выравнивание для int16
if len(data) % BYTES_PER_SAMPLE:
data = data[:-(len(data) % BYTES_PER_SAMPLE)]
stream.write(data)
proc.wait()
Она использует библиотеку sounddevice для воспроизведения аудио в реальном времени через PulseAudio. Функция обрабатывает ошибки, такие как отсутствие файла или пустое содержимое, и выходит с кодом ошибки в случае проблем.
Для запуска используйте команду:
python3 piper-stream.py hello-repka-pi.txt
Вы можете увидеть на консоли сообщение, связанное с недостаточной производительностью процессора:
ALSA lib pcm.c:8568:(snd_pcm_recover) underrun occurred
Его можно игнорировать, оно не влияет на качество звука.
Сервер синтеза речи на базе Piper и Repka-Pi 4 #
Чтобы ваша программа могла отправлять текстовые сообщения на синтезатор, я подготовил программу сервера синтеза речи на базе Piper и FastAPI. Для воспроизведения аудио используется библиотека sounddevice.
В этом сервере реализовано разделение HTTP-обработчиков и воспроизведение аудио с помощью многопоточности и очереди задач.
Сервер запускается на микрокомпьютере Perka-Pi 4 и занимает порт 8000 локального сетевого интерфейса. К нему можно обращаться как непосредственно с узла Repka-Pi, на котором работает сервер, так и с другого узла по сети и адресу IP сервера.
Для отправки текста серверу синтеза можно использовать такую команду:
curl -X POST http://192.168.0.18:8000/say -H "Content-Type: application/json" -d '{"text": "Привет! Я синтезирую речь на Репка Пай."}'
Сервер удобен тем, что программа клиента может быстро передать ему строку текста для синтеза и сразу же продолжить своё выполнение. Синтез будет выполняться одновременно с работой программы клиента в другом потоке.
Задержка при получении синтезированной речи составляет от одной до нескольких секунд и зависит от длины передаваемого текста.
Далее в статье вы также найдёте исходный код клиента, отправляющего подобный запрос из программы, составленной на Python.
Исходный код сервера #
Исходный текст сервера tts_server_pcm.py опубликован в моём репозитории на GitHub. При запуске он загружает и инициализирует модели, чтобы не выполнять эту длительную операцию каждый раз при получении текста для синтеза.
Для установки зависимостей используйте команду:
pip3 install fastapi uvicorn sounddevice piper-tts
Перечислю основные функции и их назначение.
Функция synthesize_text преобразует текст с аудиоданные. Она разделяет входной текст на строки, очищает строки от лишних пробелов и запускает последовательный синтез каждой строки с использованием модели Piper.
Далее она объединяет полученные фрагменты аудио в один массив, добавляет к нему начальную и конечную паузы для предотвращения проглатывания начальных и конечных звуков.
Выполнив все эти действия, функция возвращает аудиоданные в формате массива int16 numpy.
Для управления воспроизведением аудио в отдельном потоке используется класс AudioPlayerThread.
Метод init_stream этого класса создаёт и настраивает аудио поток через sounddevice, конфигурируя необходимые параметры.
Метод run запускает воспроизведение в отдельном потоке.
Метод audio_worker, играющий роль фонового обработчика очереди задач, создаёт бесконечный цикл обработки задач из очереди. В этом цикле происходит ожидание доступных задач, вызывается синтез звука и запуск потока воспроизведения.
Контекстный менеджер lifespan управляет жизненным циклом приложения. При запуске он инициализирует фоновый поток audio_worker и стартует его в режиме демона. При остановке — очищает очередь от ожидающих задач и завершает работу.
Теперь о маршрутах.
Чтобы принять текст для синтеза и воспроизведения определен маршрут POST /say. Он проверяет входные данные, добавляет задачи в фоновую очередь и сразу возвращает ответ клиенту без ожидания воспроизведения синтезированной речи.
Пример вызова маршрута /say:
curl -X POST http://192.168.0.18:8000/say -H "Content-Type: application/json" -d '{"text": "Привет! Я синтезирую речь на Репка Пай."}'
Маршрут GET /status позволяет получить текущее состояние сервера. Он возвращает JSON с информацией об общем статусе сервера, факте воспроизведения в данный момент, о количестве задач в очереди и частоте дискретизации аудио.
Пример вызова и ответа маршрута /status, когда сервер готов, но не занят синтезом речи:
curl -X GET http://192.168.0.18:8000/status
А это пример ответа, когда сервер занят синтезом речи:
curl -X GET http://192.168.0.18:8000/status
Если сервер занят синтезом, и в очереди еще два текста, ответ будет такой:
curl -X GET http://192.168.0.18:8000/status
Unit-файл для запуска синтезатора #
Для того чтобы сервер синтеза речи запускался автоматически при загрузке OS на Repka-Pi, создайте Unit-файл /etc/systemd/system/tts-server.service:
[Unit]
Description=TTS Server
After=pulseaudio.service
Wants=pulseaudio.service
[Service]
Type=simple
User=root
Group=audio
WorkingDirectory=/root/tts-server
Environment="PULSE_SERVER=unix:/run/user/0/pulse/native"
Environment="PULSE_COOKIE=/run/user/0/pulse/cookie"
# Запуск
ExecStart=/usr/bin/python3 /root/tts-server/tts_server_pcm.py
Restart=on-failure
RestartSec=5
NoNewPrivileges=no
PrivateTmp=no
ProtectSystem=no
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target
Для запуска сервера используйте такие команды:
sudo systemctl daemon-reload
sudo systemctl start tts-server
После запуска проверьте статус сервиса:
sudo systemctl status tts-server
Также включите автозапуск при загрузке:
sudo systemctl enable tts-server
С помощью следующей команды вы сможете просматривать журнал сервиса:
sudo journalctl -u tts-server -f
Клиент сервера синтеза речи #
Как я уже писал выше, для отправки текста на сервер синтеза речи можно использовать команду curl такого вида:
curl -X POST http://192.168.0.18:8000/say -H "Content-Type: application/json" -d '{"text": "Привет! Я синтезирую речь на Репка Пай."}'
Здесь нужно указать адрес IP вашей Repki-Pi, который можно узнать из консоли при помощи команды «ip -a».
В файле tts_client_pcm_play.py вы найдете пример несложного клиента для описанного в этой статье синтезатора речи:
import sys
import requests
import json
def main():
if len(sys.argv) != 2:
print("Использование: python client.py <путь_к_файлу>")
print("Пример: python client.py text.txt")
sys.exit(1)
# Получаем путь к файлу из аргументов
file_path = sys.argv[1]
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read().strip()
if not text:
print("Файл пуст!")
sys.exit(1)
data = {"text": text}
# URL сервера (замените на актуальный, если отличается)
url = "http://192.168.0.18:8000/say"
response = requests.post(
url,
headers={"Content-Type": "application/json"},
data=json.dumps(data, ensure_ascii=False).encode('utf-8')
)
if response.status_code 200:
print("Запрос успешно отправлен!")
print(f"Ответ сервера: {response.text}")
else:
print(f"Ошибка: {response.status_code}")
print(f"Ответ: {response.text}")
except FileNotFoundError:
print(f"Файл не найден: {file_path}")
sys.exit(1)
except requests.exceptions.ConnectionError:
print("Не удалось подключиться к серверу. Проверьте адрес и порт.")
sys.exit(1)
except Exception as e:
print(f"Произошла ошибка: {str(e)}")
sys.exit(1)
if name "_main_":
main()
Эта программа читает текст из файла, который передаётся ей в качестве параметра, а затем отправляет его через POST-запрос на сервер распознавания речи. Вы можете запустить её такой командой:
python3 tts_client_pcm_play.py hello-repka-pi.txt
Итоги #
На сегодняшний день для микрокомпьютера Repka-Pi 4 доступны как очень легковесные синтезаторы речи, работающие быстро, но с невысоким качеством, так и качественные синтезаторы, такие как Piper TTS.
В статье я рассмотрел только такие, которые способны «говорить» на русском языке при доступном объёме оперативной памяти 2 ГБайта и без GPU. Ожидаю, что с появлением более производительного микрокомпьютера Repka-Pi 5 можно будет использовать и другие модели, а также ускорить синтез звука.
Количество проектов и задач, в которых можно использовать данные решения, просто огромное. Озвучивание входящих сообщений, собственная читалка книг и т.д. и т.п. А если брать за основу своих проектов верхне-уровневую логику как на картинке ниже
и добавить к ней распознавание речи как в статье и ещё в качестве модуля исполнения команд добавить собственный алгоритм - от самого простого набора условий, до системы поддержки принятия решений с применением нейросетевых моделей для принятия решения, то можно сделать свою локальную условную “алису” или помощника или общаться с роботом и получать от него голосовые запросы на подтверждение действий или принимаемых решений… и тут место для реализации замыслов и фантазий просто не ограничено.
Если Вам понравились эксперименты с синтезаторами речи на Repka-Pi, ставьте лайки, этот функционал недавно добавлен в РепкаБлоге и используйте Идеи из этой статьи в своих проектах.
Интересных творческих проектов!
Автор: Александр Фролов